了解PE的结构:https://zhuanlan.zhihu.com/p/31967907
作为练手的记录, 学习性不是很强;
记录一些术语:
魔术码 = 幻码 = 特征码;
结构体中单个内容 = 字段;
rva = 内存中偏移;
foa = 文件中偏移;
静态 = 文件中的处理;
动态 = 内存中的处理;
IAT = 导入地址表 = import address table
INT = 导入名称表 = import name table
读取文件
定义一些简单的类型:
1
2
3
4
| typedef unsigned char UINT8;
typedef unsigned short int UINT16;
typedef unsigned int UINT32;
typedef unsigned long int UINT64;
|
解析一个PE文件首先需要读取二进制内容;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
int get_file_size(FILE* fp)
{
fseek(fp, 0, SEEK_END);
int size = ftell(fp);
fseek(fp, 0, SEEK_SET);
return size;
}
char filename[] = "a.exe";
FILE* fp = fopen(filename, "r");
int fsize = get_file_size(fp);
UINT8* fbuffer = (UINT8*)malloc(fsize);
fread(fbuffer, 1, fsize, fp);
fclose(fp);
|
利用如上代码便可以将 a.exe 的内容复制给 fbuffer 缓冲区,之后在这个缓冲区上进行操作;
解析DOS头
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
UINT8* p_dos_header = fbuffer;
UINT16 dos_magic = (UINT16) * ((UINT16*)p_dos_header);
UINT32 pe_offset;
if (dos_magic != 0x5a4d)
{
printf("%s it's not a valid PE file.\n", filename);
free(fbuffer);
return 0;
}
else
{
pe_offset = (UINT32) * (UINT32*)(p_dos_header + 0x40 - 4);
}
|
在这里只捕获了两个重要的内容,也就是 dos magic 和 pe offset,第一个能判断这个文件是否为一个PE文件,第二能由此找到PE头,也就是常说的NT头;
解析PE头
也称NT头;
1
2
3
4
5
6
7
8
|
UINT8* p_pe_header = (p_dos_header + pe_offset);
UINT32 pe_magic = (UINT32) * ((UINT32*)p_pe_header);
if (pe_magic != 0x4550)
{
printf("%s it's pe magic number wrong: %x\n", filename, pe_magic);
}
|
根据dos头里获得的pe偏移,利用dos头指针找到pe头,由此给出pe魔术码;
解析file头
file头,可称为标准PE头;
1
2
3
4
5
6
7
8
|
UINT8* p_file_header = p_pe_header + 4;
UINT16 machine_num = (UINT16) * ((UINT16*)p_file_header);
UINT16 number_of_sections = (UINT16) * (UINT16*)(p_file_header + 2);
UINT16 size_of_optional_header = (UINT16) * (UINT16*)(p_file_header + 16);
UINT16 file_characteristics = (UINT16) * (UINT16*)(p_file_header + 18);
printf("it's machine number is %xh\n", machine_num);
|
根据pe头能找到file头,给出其中4个重要内容,由上往下依次是:
- CPU架构码,代表能在什么架构上运行,0值默认都行;
- 节区数量,记录节的总数;
- 可选头大小,默认e0h是32位, f0h是64位;
- 特性,每位都代表一个内容,具体是什么用 010 editor 查看;
之后便给出CPU架构码;
解析可选头
optional头,也称可选PE头;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
UINT8* p_optional_header = p_file_header + 20;
UINT16 optional_magic = (UINT16) * ((UINT16*)p_optional_header);
UINT32 oep_offset = (UINT32) * (UINT32*)(p_optional_header + 16);
UINT64 image_base = (UINT64) * (UINT64*)(p_optional_header + 24);
UINT32 section_alignment = (UINT32) * (UINT32*)(p_optional_header + 32);
UINT32 file_alignment = (UINT32) * (UINT32*)(p_optional_header + 36);
UINT32 size_of_image = (UINT32) * (UINT32*)(p_optional_header + 56);
UINT32 size_of_headers = (UINT32) * (UINT32*)(p_optional_header + 60);
UINT16 dll_characteristics = (UINT16) * (UINT16*)(p_optional_header + 70);
if (size_of_optional_header == 0xe0 && optional_magic == 0x10b)
printf("standard 32bit mode.\n");
else if(optional_magic == 0x10b)
printf("32bit mode but size of optional header: %x\n", size_of_optional_header);
else if(size_of_optional_header == 0xf0 && optional_magic == 0x20b)
printf("standard 64bit mode.\n");
else if (optional_magic == 0x20b)
printf("64bit mode but size of optional header: %x\n", size_of_optional_header);
printf("OEP is at 0x%x\n", image_base + oep_offset);
|
根据PE头能找到可选头,给出其中8个重要内容,从下往上依次是:
- 可选魔术码,标准是32位还是64位,分别用10bh和20bh代表;
- oep偏移,相对加载内存地址的程序入口地址的偏移,配合image_base食用;
- 内存地址实际加载处,注意,如果开了 随机基址(动态基址)则无用,动态基址在第8个里可查看是否开启;
- 内存中对齐,默认1000h;
- 文件中对齐,默认200h;
- 内存中整个文件大小;
- 文件中所有头部大小,包括 dos头,dos存根,nt头,节区头;
- 类似之前的特性,也是每一位代表一个内容,具体用 010 editor 查看;
之后给出位模式和oep地址;
解析节区头
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
UINT8* p_section_header = p_optional_header + size_of_optional_header;
char section_name[9];
UINT32 VA;
UINT32 PA;
for (int i = 0; i < number_of_sections; i++)
{
for (int j = 0; j < 8; j++)
{
section_name[j] = p_section_header[j];
}
section_name[8] = '\0';
VA = (UINT32) * (UINT32*)(p_section_header + 12);
PA = (UINT32) * (UINT32*)(p_section_header + 20);
VA += image_base;
PA += image_base;
printf("%-40s VA 0x%016jx \n PA 0x%016jx \n--------------------\n", section_name, VA, PA);
p_section_header += 0x28;
}
|
利用可选头和其大小,跳转到节区头,并利用文件头中获取的节区数量进行循环打印名称,并打印其中每个节区的内存中(VA)地址和文件中(PA)地址;
关于对齐和偏移
偏移都是相对image base而言;
因为在文件中和内存中有不同的对齐,所以才有不同的偏移值,而对齐是相对于区段而言,区段与区段之间,头与区段之间会填充对齐;
当知晓一个地址的VA偏移,且知晓这个地址属于哪个区段,便可得出这个地址的PA偏移;
why?
因为区段内不存在对齐改变偏移,所以有等式:地址VA - 区段VA = 区段与地址的距离
地址PA - 区段PA = 区段与地址的距离
所以有 地址PA = 地址VA - 区段VA + 区段PA;
定义转换函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| UINT32 vtop(UINT32 rva, UINT8* p_section_header, UINT16 number_of_sections)
{
UINT32 VA;
UINT32 PA;
UINT32 true_size;
for (int i = 0; i < number_of_sections; i++)
{
VA = (UINT32) * (UINT32*)(p_section_header + 12);
PA = (UINT32) * (UINT32*)(p_section_header + 20);
true_size = (UINT32) * (UINT32*)(p_section_header + 8);
if ((rva >= VA) && (rva < VA + true_size))
{
return (rva - VA + PA);
}
p_section_header += 0x28;
}
printf("rva error\n\n");
return 0;
}
|
当rva存在在一个区段的内部时,也就是if判断,就可以执行转换了,如果没找到,就是错误的rva;
打印导出表
导出表是可选头最后一个结构体数组的第一个索引来寻找的;
注意:导出表很多内容本质是rva,导出表结构可自行百度;
所以找到特别的结构体数组:
1
2
3
|
UINT32 datadirarray_index = (UINT32) * (UINT32*)(p_section_header - 0x84);
UINT8* datadirarray = p_section_header - 0x80;
|
因为32位和64位op头长度不同,所以都能用的情况就是用节区头去反着找;
这个数组的每个结构体都只有一个实际的内容,就是记录表或者项目的rva;
之后根据 datadirarray 找到导出表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
if ((UINT32) * (UINT32*)(datadirarray) != 0)
{
UINT8* export_table = vtop((UINT32) * (UINT32*)(datadirarray), p_section_header, number_of_sections) + fbuffer;
UINT32 etnamead = (UINT32) * (UINT32*)(export_table + 12);
UINT8* etname = vtop(etnamead, p_section_header, number_of_sections) + fbuffer;
UINT32 number_of_functions = (UINT32) * (UINT32*)(export_table + 20);
UINT32 number_of_names = (UINT32) * (UINT32*)(export_table + 24);
UINT8* ad_of_funcs = vtop((UINT32) * (UINT32*)(export_table + 28), p_section_header, number_of_sections) + fbuffer;
UINT8* ad_of_names = vtop((UINT32) * (UINT32*)(export_table + 32), p_section_header, number_of_sections) + fbuffer;
UINT8* ad_of_ordis = vtop((UINT32) * (UINT32*)(export_table + 36), p_section_header, number_of_sections) + fbuffer;
printf("\n%s\n\n", etname);
int flag;
for (int i = 0; i < number_of_functions; i++)
{
flag = 0;
printf("0x%016jx", (UINT32) * (UINT32*)(ad_of_funcs + 4 * i) + image_base);
for (int j = 0; j < number_of_names; j++)
{
flag = 1;
if (i == (UINT16) * (UINT16*)(ad_of_ordis + 2 * j))
{
printf(" %3d %s\n", i, vtop((UINT32) * (UINT32*)(ad_of_names + 4 * j), p_section_header, number_of_sections) + fbuffer);
flag = 0;
break;
}
}
if (flag == 1)
{
printf(" ---\n");
}
}
}
else
{
printf("no export..\n");
}
|
首先需要有 导出表,也就是 datadirarray[0] 有存在的rva,然后利用rva去静态地找到导出表;
之后同样的道理,找到导出表名称,接着是导出函数数,以及有名称的函数数;
然后是三个表:函数地址表,函数序数表,函数名称表;
关系如下:
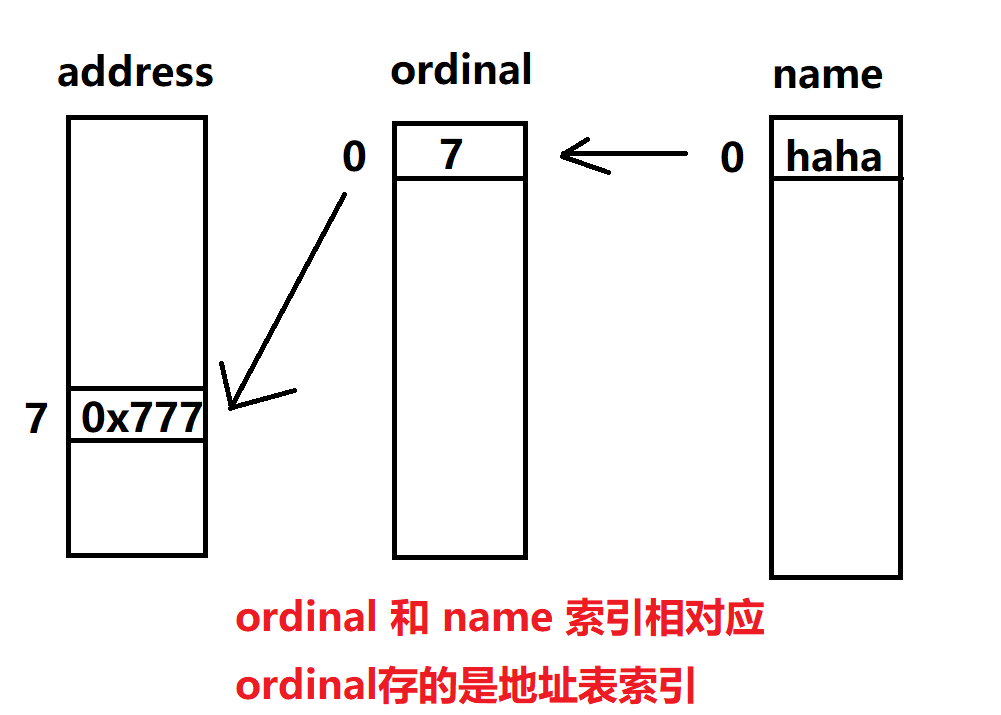
所以才有打印时的循环操作:
- 首先根据整体数量操作,打印出索引对应地址;
- 然后进入内层循环,找有名称的函数;
- 当地址索引和序数表内容相同时,也就是if判断,利用当前序数表索引打印函数名称;
- 设置的flag位算信号量,打印没名称函数;
打印导入表
关于dll载入
显式加载时,调用文件会留下函数名,以rva字符串形式保存在文件中;
主文件和dll文件被扔到同一个进程中;
加载到内存时,loadlibrary函数做了 将dll文件的 imagebase 地址赋予到本文件指针,所以可以操作dll文件的头部;
可以简单理解 通过dll的导出表 将存放函数名rva的地方改成了对应的函数地址;
由此,dll中的函数被调用;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
if ((UINT32) * (UINT32*)(datadirarray + 8) != 0)
{
UINT8* import_table = vtop((UINT32) * (UINT32*)(datadirarray + 8), p_section_header, number_of_sections) + fbuffer;
while (import_table != NULL)
{
UINT8* original_first_thunk = import_table;
UINT32 itnamead = (UINT32) * (UINT32*)(import_table + 12);
UINT8* itname = (itnamead, p_section_header, number_of_sections) + fbuffer;
printf("Import Table:\n");
printf("%s\n\n", itname);
UINT8* name_stru = vtop((UINT32) * (UINT32*)(original_first_thunk), p_section_header, number_of_sections) + fbuffer;
while (name_stru != NULL)
{
UINT32 ntype = (UINT32) * (UINT32*)name_stru;
if (ntype & 0x80000000)
{
printf("import by ordinal %40d\n", ntype & 0x7fffffff);
}
else
{
UINT8* n_stru = vtop(ntype, p_section_header, number_of_sections) + fbuffer;
n_stru += 2;
printf("import by name %40s\n", n_stru);
}
name_stru += 8;
}
printf("--------------------\n");
import_table += 0x14;
}
}
else
{
printf("no import..\n");
}
printf("\n");
|
导入表结构如下:
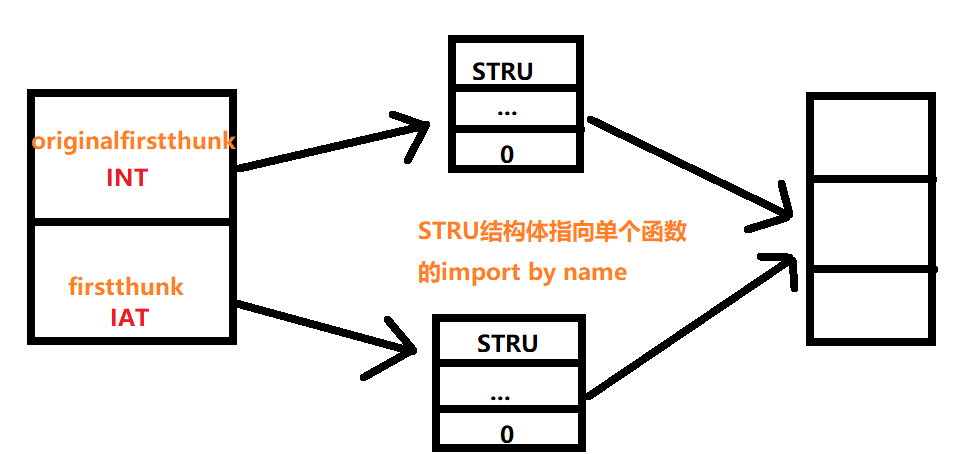
先根据datadirarray拿到import表,每个导入的文件都会有一个import表,所以import表可能有多个,所以循环遍历;
在import表里有 IAT 和 INT ,这里拿的是 INT : original_first_thunk,之后获取名称;
STRU在上述代码称为name_stru,是该导入表的所有函数,所以又用一个循环遍历;
1
2
3
4
| typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
BYTE Name[1];
}
|
INT里的每一个STRU会指向一个结构体: import by name,里面可能是序数导入的函数,也可能是名称导入的函数,区分就是看最高位是否是1,如果是名字导入,则第二个字节之后就是名称的rva;
在dll链接之后,根据dll自身的导出表中的函数地址,一一对应地修改自身exe文件的导入表中IAT指向,此时IAT便指向了真实的地址;
整体效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
| #include<iostream>
#include<cstdlib>
using namespace std;
typedef unsigned char UINT8;
typedef unsigned short int UINT16;
typedef unsigned int UINT32;
typedef unsigned long int UINT64;
int fapi = 0;
UINT32 vtop(UINT32 rva, UINT8* p_section_header, UINT16 number_of_sections)
{
UINT32 VA;
UINT32 PA;
UINT32 true_size;
for (int i = 0; i < number_of_sections; i++)
{
VA = (UINT32) * (UINT32*)(p_section_header + 12);
PA = (UINT32) * (UINT32*)(p_section_header + 20);
true_size = (UINT32) * (UINT32*)(p_section_header + 8);
if ((rva >= VA) && (rva < VA + true_size))
{
if (fapi == 1)
{
return (rva - VA + PA - 1);
}
return (rva - VA + PA);
}
p_section_header += 0x28;
}
printf("rva error\n\n");
return 0;
}
int get_file_size(FILE* fp)
{
fseek(fp, 0, SEEK_END);
int size = ftell(fp);
fseek(fp, 0, SEEK_SET);
return size;
}
int main(int argc, char* argv[])
{
char mode[3];
if (argc < 2)
{
printf("\nUsage: %s + ./file_you_want_know\n\n", argv[0]);
return 0;
}
if (argc > 2)
{
sprintf(mode, "%s", argv[2]);
}
char* filename = argv[1];
FILE* fp;
if ((fp = fopen(filename, "r")) == NULL)
{
printf("\nfile path maybe wrong?\n\n");
return 0;
}
int fsize = get_file_size(fp);
UINT8* fbuffer = (UINT8*)malloc(fsize);
fread(fbuffer, 1, fsize, fp);
fclose(fp);
UINT8* p_dos_header = fbuffer;
UINT16 dos_magic = (UINT16) * ((UINT16*)p_dos_header);
UINT32 pe_offset;
if (dos_magic != 0x5a4d)
{
printf("\n%s it's not a valid PE file.\n\n", filename);
free(fbuffer);
return 0;
}
else
{
pe_offset = (UINT32) * (UINT32*)(p_dos_header + 0x40 - 4);
}
UINT8* p_pe_header = (p_dos_header + pe_offset);
UINT32 pe_magic = (UINT32) * ((UINT32*)p_pe_header);
if (pe_magic != 0x4550)
{
if ((UINT32) * (UINT32*)(p_pe_header - 1) == 0x4550)
p_pe_header -= 1;
else
printf("\n%s it's pe magic number wrong: %x\n", filename, pe_magic);
}
UINT8* p_file_header = p_pe_header + 4;
UINT16 machine_num = (UINT16) * ((UINT16*)p_file_header);
UINT16 number_of_sections = (UINT16) * (UINT16*)(p_file_header + 2);
UINT16 size_of_optional_header = (UINT16) * (UINT16*)(p_file_header + 16);
UINT16 file_characteristics = (UINT16) * (UINT16*)(p_file_header + 18);
printf("\nit's machine number is %xh\n", machine_num);
UINT8* p_optional_header = p_file_header + 20;
UINT16 optional_magic = (UINT16) * ((UINT16*)p_optional_header);
UINT32 oep_offset = (UINT32) * (UINT32*)(p_optional_header + 16);
UINT64 image_base = (UINT64) * (UINT64*)(p_optional_header + 24);
UINT32 section_alignment = (UINT32) * (UINT32*)(p_optional_header + 32);
UINT32 file_alignment = (UINT32) * (UINT32*)(p_optional_header + 36);
UINT32 size_of_image = (UINT32) * (UINT32*)(p_optional_header + 56);
UINT32 size_of_headers = (UINT32) * (UINT32*)(p_optional_header + 60);
UINT16 dll_characteristics = (UINT16) * (UINT16*)(p_optional_header + 70);
if (size_of_optional_header == 0xe0 && optional_magic == 0x10b)
printf("standard 32bit mode.\n");
else if (optional_magic == 0x10b)
printf("32bit mode but size of optional header: %x\n", size_of_optional_header);
else if (size_of_optional_header == 0xf0 && optional_magic == 0x20b)
printf("standard 64bit mode.\n");
else if (optional_magic == 0x20b)
printf("64bit mode but size of optional header: %x\n", size_of_optional_header);
printf("OEP is at 0x%x\n\n", image_base + oep_offset);
UINT8* p_section_header = p_optional_header + size_of_optional_header;
if (*p_section_header == 0)
p_section_header += 1;
char section_name[9];
UINT32 VA;
UINT32 PA;
if (mode[0] == 45 && mode[1] == 115)
{
for (int i = 0; i < number_of_sections; i++)
{
for (int j = 0; j < 8; j++)
{
section_name[j] = p_section_header[j];
}
section_name[8] = '\0';
VA = (UINT32) * (UINT32*)(p_section_header + 12);
PA = (UINT32) * (UINT32*)(p_section_header + 20);
VA += image_base;
PA += image_base;
printf("%-40s VA 0x%016jx \n PA 0x%016jx \n--------------------\n", section_name, VA, PA);
p_section_header += 0x28;
}
p_section_header = p_optional_header + size_of_optional_header;
printf("\n");
}
UINT32 datadirarray_index = (UINT32) * (UINT32*)(p_section_header - 0x84);
UINT8* datadirarray = p_section_header - 0x80;
if ((mode[0] == 45 && mode[1] == 116) || (mode[0] == 45 && mode[2] == 116))
{
if ((UINT32) * (UINT32*)(datadirarray) != 0)
{
export_s:
UINT8* export_table = vtop((UINT32) * (UINT32*)(datadirarray), p_section_header, number_of_sections) + fbuffer;
UINT32 etnamead = (UINT32) * (UINT32*)(export_table + 12);
UINT8* etname = vtop(etnamead, p_section_header, number_of_sections) + fbuffer;
if (etname == fbuffer)
{
fapi = 1;
printf("correct already..\n\n");
goto export_s;
}
UINT32 number_of_functions = (UINT32) * (UINT32*)(export_table + 20);
UINT32 number_of_names = (UINT32) * (UINT32*)(export_table + 24);
UINT8* ad_of_funcs = vtop((UINT32) * (UINT32*)(export_table + 28), p_section_header, number_of_sections) + fbuffer;
UINT8* ad_of_names = vtop((UINT32) * (UINT32*)(export_table + 32), p_section_header, number_of_sections) + fbuffer;
UINT8* ad_of_ordis = vtop((UINT32) * (UINT32*)(export_table + 36), p_section_header, number_of_sections) + fbuffer;
printf("Export Table:\n");
printf("%s\n\n", etname);
int flag;
for (int i = 0; i < number_of_functions; i++)
{
flag = 0;
printf("0x%016jx", (UINT32) * (UINT32*)(ad_of_funcs + 4 * i) + image_base);
for (int j = 0; j < number_of_names; j++)
{
flag = 1;
if (i == (UINT16) * (UINT16*)(ad_of_ordis + 2 * j))
{
printf(" %3d %s\n", i, vtop((UINT32) * (UINT32*)(ad_of_names + 4 * j), p_section_header, number_of_sections) + fbuffer);
flag = 0;
break;
}
}
if (flag == 1)
{
printf(" ---\n");
}
}
}
else
{
printf("no export..\n");
}
printf("\n");
if ((UINT32) * (UINT32*)(datadirarray + 8) != 0)
{
UINT8* import_table = vtop((UINT32) * (UINT32*)(datadirarray + 8), p_section_header, number_of_sections) + fbuffer;
while (import_table != NULL)
{
UINT8* original_first_thunk = import_table;
UINT32 itnamead = (UINT32) * (UINT32*)(import_table + 12);
UINT8* itname = vtop(itnamead, p_section_header, number_of_sections) + fbuffer;
printf("Import Table:\n");
printf("%s\n\n", itname);
UINT8* name_stru = vtop((UINT32) * (UINT32*)(original_first_thunk), p_section_header, number_of_sections) + fbuffer;
while (name_stru != NULL)
{
UINT32 ntype = (UINT32) * (UINT32*)name_stru;
if (ntype & 0x80000000)
{
printf("import by ordinal %40d\n", ntype & 0x7fffffff);
}
else
{
UINT8* n_stru = vtop(ntype, p_section_header, number_of_sections) + fbuffer;
n_stru += 2;
printf("import by name %40s\n", n_stru);
}
name_stru += 8;
}
printf("--------------------\n");
import_table += 0x14;
}
}
else
{
printf("no import..\n");
}
printf("\n");
}
free(fbuffer);
return 0;
}
|
-s -t 模式打印节区和两张表;
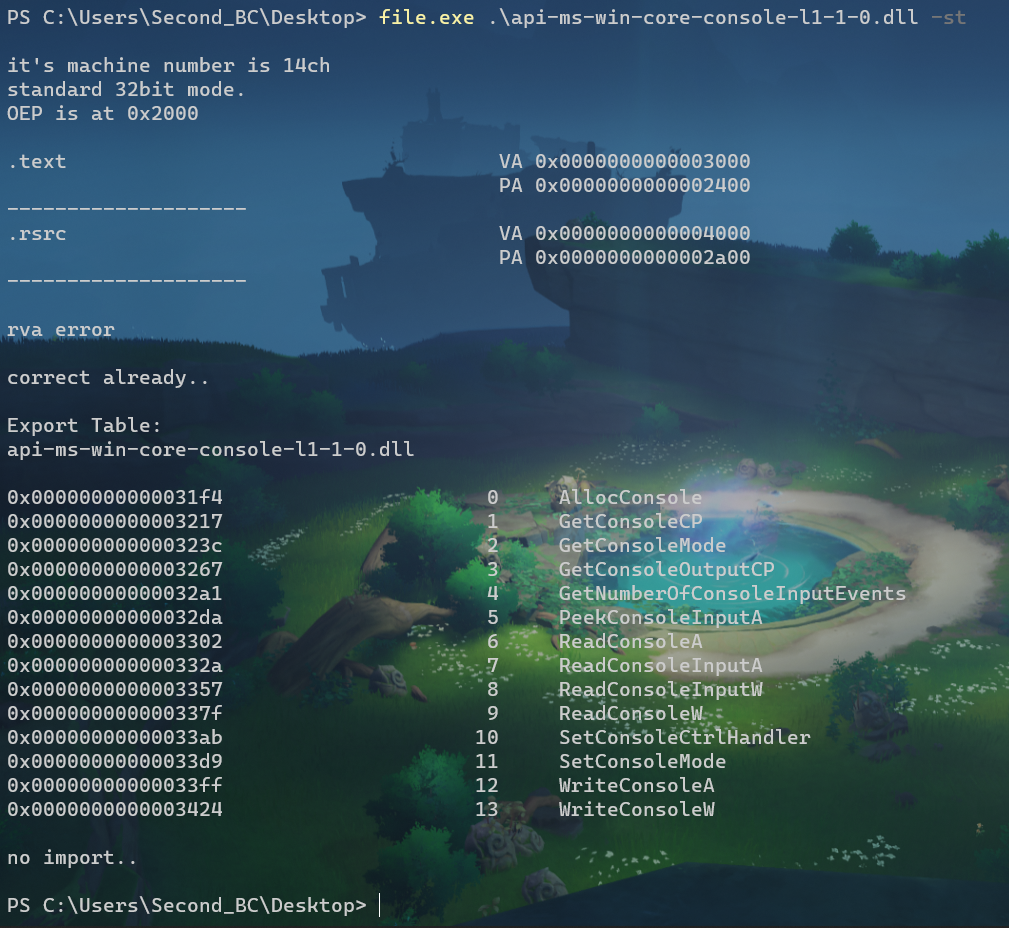
总结
只能说,纯手撸会有些不完善的bug,逻辑上和测试上是没问题的,有些偏移有问题,用微软自带的结构体应该是能解决这个毛病的,而且更好写,想用什么内容直接指就行了;
没有模块化也是bug模糊的问题之一;
写下来对PE有更深刻的理解;
