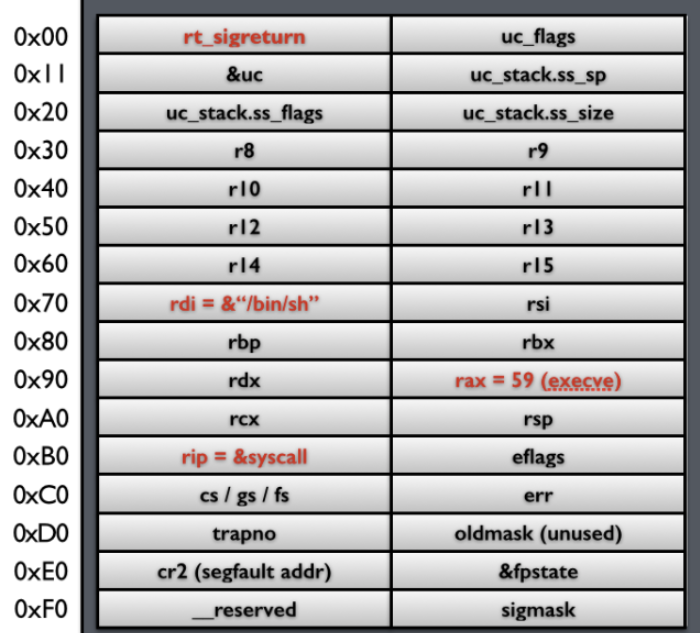
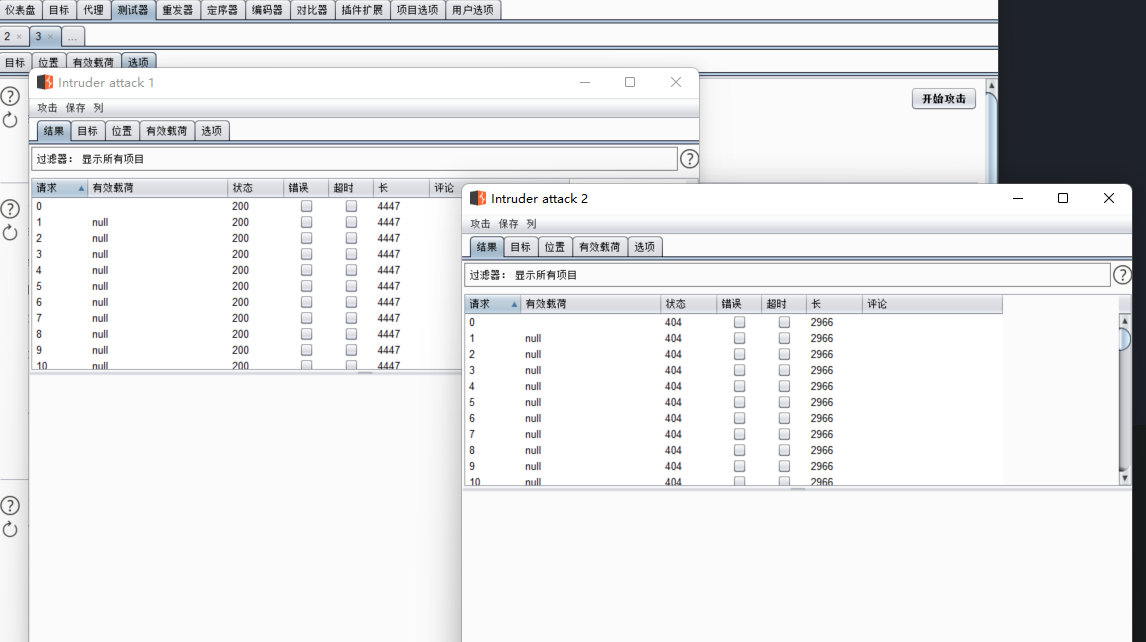
环境
对于以下理论,不提及环境均是32位操作系统上的;
使用VS系列搭配对应windows版本和SDK,WDK版本进行开发;
这里使用VS2015,win10,SDK和WDK版本10.0.14393(不要用VS2022,写不了32位驱动);
对于驱动环境的搭建在b站有详细的教程;
简略来说,先要搜索WDK,进入其下载界面,找到与之对应windows系统版本的WDK下载,但是不要安装,只是看清楚WDK的版本,下载与之对应的VS版本之后,选择同样版本的SDK下载,最后才安装WDK;
这个流程会帮你省很多不必要的麻烦;
在创建项目的界面此时就会有Driver选项了;
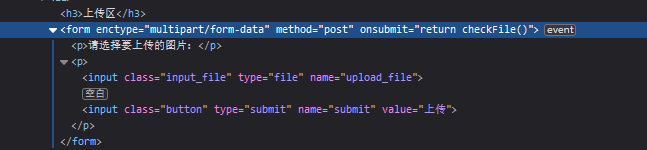
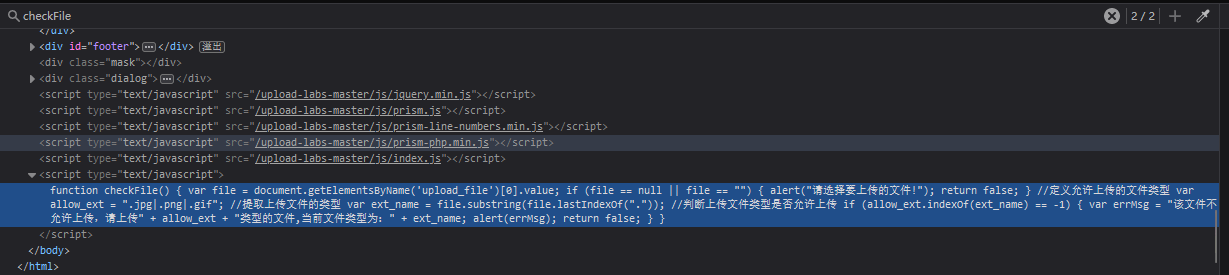
选择 空WDM驱动 模板,进入后删除其中自带的文件,创建一个main.c即可开始编写;
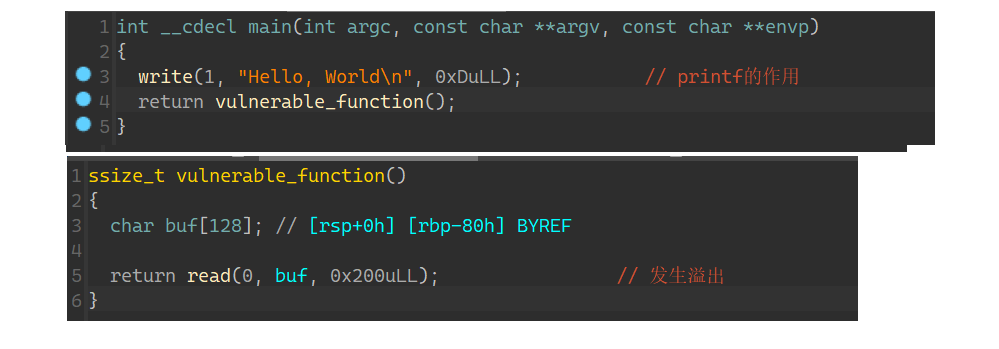
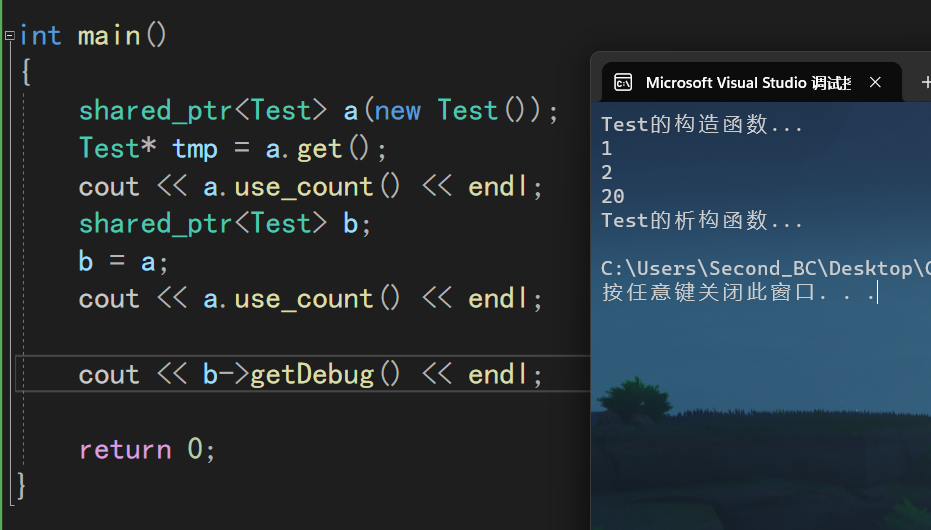
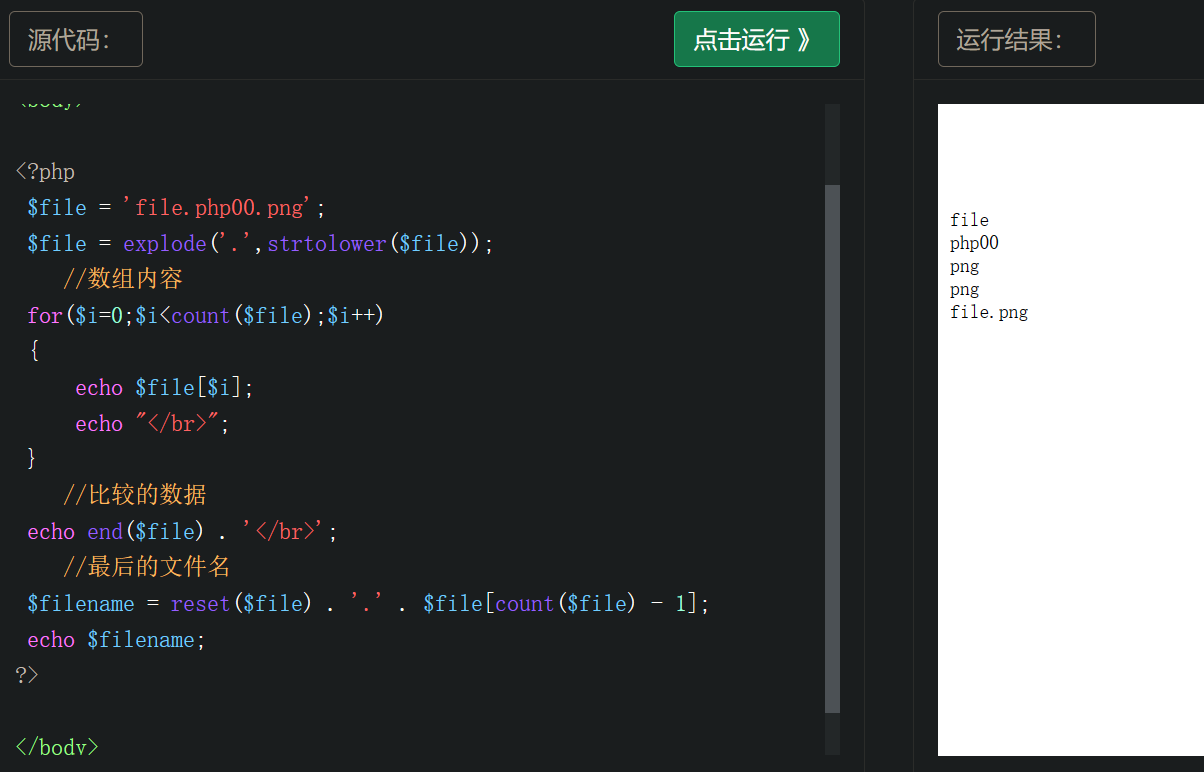
一个具体的驱动模板如下(类似于控制台程序的 int main()):
1 |
|
需要注意的是,把属性里面的把警告视为错误给关了,不然编译不通过;
当你编译通过,生成了sys文件之后,说明环境没问题了;
对于驱动的双机调试,需要准备一个windows虚拟机,我用到的是win7(x86);
打开虚拟机,用管理员方式打开cmd,输入如下的指令:
1 | bcdedit /copy {current} /d debug #拷贝当前引导为一个新引导叫做debug 这条指令完之后会获得一个ID |
之后重启虚拟机,会发现可以选择debug进入,进入之后会一直卡着黑屏等待连接;
此时关机,在设置中添加一个(串行端口)硬件:
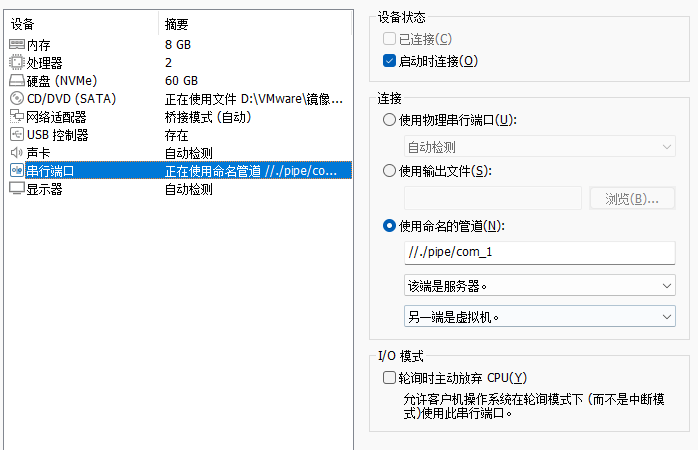
选择使用命名的管道,管道名称输入 //./pipe/com_1 (这个名称可以随便com_1 com_2都行);
把打印机硬件给移除掉,因为它会占用端口;
这个时候找到你下载的WDK里面的windbg.exe,在Windows Kits文件夹里;
新建一个bat文件,编辑内容为如下:
1 | cmd /k "D:\Windows Kits\10\Debuggers\x64\windbg.exe" -y SRV*D:\symbol*http://msdl.microsoft.com/download/symbols -b -k com:port=//./pipe/com_1,baud=115200,pipe |
windbg路径填入自己对应的就行,要说明以下两条:
1 | com:port=//./pipe/com_1,baud=115200,pipe #对应的管道名称要一样和vm里设置的 |
此时打开这个bat文件,就可以开始调试win7了;
和VS调试一样,用F9断点,F10步过,F11步入进行;
当断下点的时候,可以发现虚拟机win7动不了,冻住了,就说明挂载连接成功,可以进行调试;
保护模式
这里是从80386架构引申出来的理论:
实模式是在实地址上进行的,位长16,没有虚拟内存,虚拟地址的说法,一切都在物理地址上进行寻址;
寻址公式:
$$
段地址 × 10h + 逻辑地址(偏移) == 线性地址(实际物理地址)
$$
例如一条指令如下:
1 | mov ax, word ptr ds:[0x15555] |
那么实际上ax给到的值是 2000 * 10 + 15555 = 35555h地址里面的;
这个模式并不安全,在其他进程里,只要知晓内核代码区域的段地址,就可以访问它的内存;
所以引出了保护模式;
保护模式在实模式的基础上增加了位长为32,同时引入虚拟地址的概念,即每个进程都是40W起始,但进程A的40W存放的东西和进程B的40W存放的地址并不相同,同时引入段页机制;
要经过一系列多级页表,缓存快表的查询最终拿到A进程40W地址的真正物理地址,在物理地址上,一个进程很可能是离散存储的;
这是内存页的概念;在windows中也有快表和页命中的机制,换出到磁盘上的页,一般在C盘的pagefile里;
对于段的解释,则是进程对于不同部分,权限的划分;
要玩转计算机,就要学好页和段的机制,如同想要pwn好,就要学好linux堆栈的机制一样;
补充知识:CISC架构页一般4k,RISC架构页一般2k;
CISC和RISC还有不同的地方在于耗电量和脉冲频率,前者会大于后者,所以跑的快;
段
引入和介绍
在32位保护模式下,段寄存器存的并不是一个实际地址,不遵守上面的规则,实则是一个表的索引;
当段寄存器通过表拿到基址之后,才遵守寻址规则,此时的(段地址*0x10)就相当于基址,但计算得到的仍然是虚拟地址,通过页表才能拿到物理地址;
所以在保护模式下的段这个概念,实际上都是虚拟的,只是和权限挂钩;
下图为段选择符(段选择子):
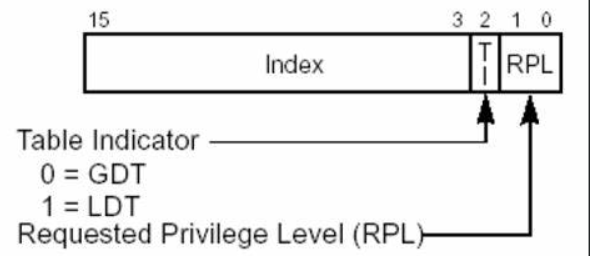
比如ds,此时存放的值为0x2b,将其转换为二进制 00000000 00101011
那么按照上述段选择符的描述进行查看: 0000000000101 0 11
此时RPL为11,代表请求权限;
TI此时为0,代表要访问的表,其中有GDT和LDT,一个是全局描述表,一个是局部描述表,一般而言都是用的GDT;
101对应10进制为:5,查找GDT表的第五项;
在windbg里,有一个命令可以查看gdt:
1 | r gdtr |
执行后能获取gdt的地址,使用dq dd查看gdt地址的存放数据,可以拿到表项内容;
对于表项的修改可以用 eq ed进行修改;
我们直接拿windbg获取的gdt表内容如下:
1 | kd> dqs fffff80259e7dfb0 |
表中每个成员占8字节;
这些成员实际上叫做段描述符: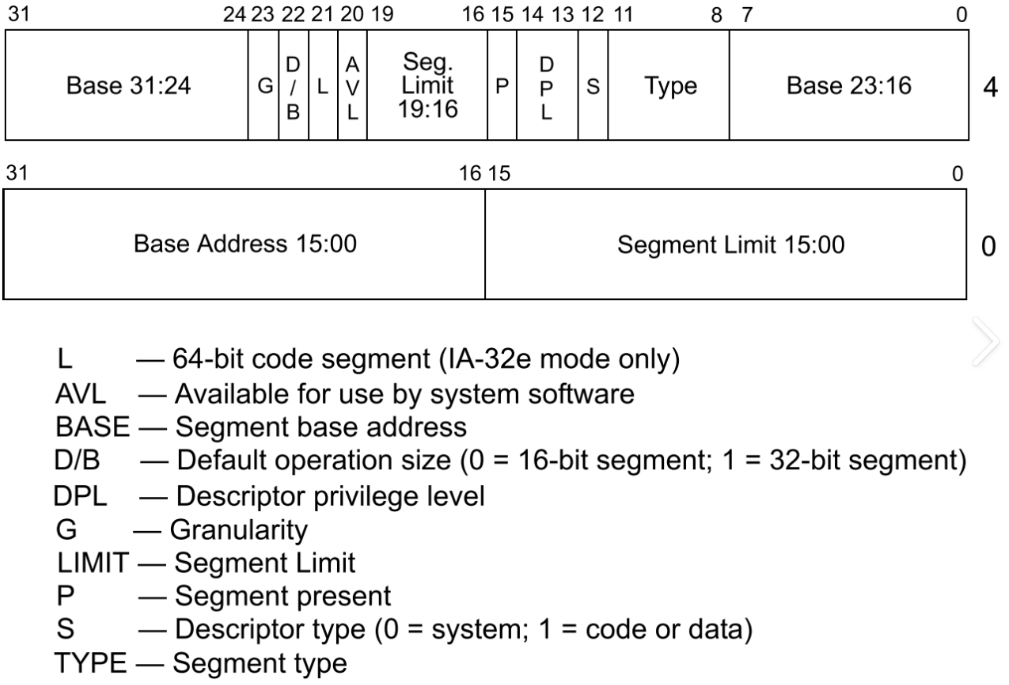
00cff300`0000ffff
其中Segment Limit是限长,允许逻辑地址访问的最大长度,在这里是ffff
Seg Limit 19:16是作为Segment Limit的高位补充,所以Segment Limit整体是f ffff
Base Address是基址,这里是 0000
同时,Base 31:24和23:16是作为Base Address的高位补充,即Base Address整体应该是00 00 0000;
那现在就剩下c f3这12bit了;
举个例子,有如下代码:
1 | mov eax,dword ptr ds:[0x12345678] |
实际上是把基址0 + 0x12345678得到的地址的内容给到了eax;
而如果ds:[]括号里面的数据大于了4G,就会异常中断;
将所有数据对应翻译如下:
limit:fffff 20位,从0开始算(如果是0,则限长为1)
base:00000000 基址为0
type:3 段的权限!
s:1
DPL:3
P(有效位):1
AVL(保留字):0
L:0 默认为0
D/B:1
G(粒度):1 这个地方为1,limit以页为单位,否则以字节为单位,此时这个段管理4G内存(limit 4G)
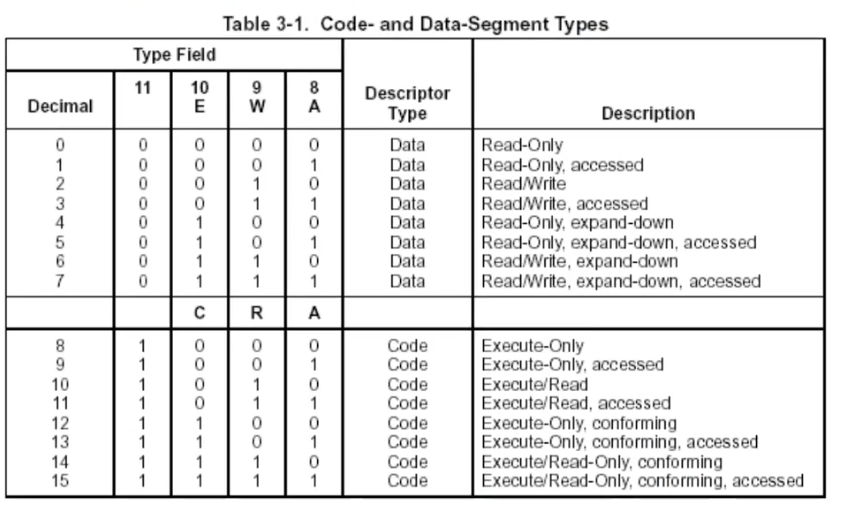
以上是type数值对应段的权限;
可以看到上面每隔一个描述,都会有一个accessed,它代表这个段被使用过;
如果将gdt一个成员设置为type:2,再给到ds这个成员,这个时候,2会+1变成3;
对于expand-down,叫做向下生长,即base和limit之间的区域变成不可访问(无权限)的状态,而其他没有包含的内存(4G中的其他地方)可以访问(和不带expand-down相反,不带的称作向上生长);
对于conforming(一致)描述是用于纯段模式下,应用层可以直接调用cs描述的代码段(内核);
当写内容到没有写权限的段时,就会发生异常中断;
从上述内容可以总结得到的信息为:需要遵守段的限长,读写权限,以及段寄存器寻表项,base是什么的内容;
对于更改cs的补充:可以直接更改ds,es,但是不允许直接更改cs,可以通过jmp进行间接更改:
1 | jmp far 0x4b:address |
它会跳转后将cs更改为0x4b,称为跨段跳转,不提权;
在win10上貌似不能用这样的方法改动cs?(为什么呢?)
也可以使用call:
1 | call far 0x4b:address |
这个时候栈里会压入旧的CS值,以及返回地址;
栈结构:
| eip |
|---|
| cs |
在内联汇编中还不能直接写call一个立即数,需要用到一个数组:
1 | //32位 |
D/B
对于每个段描述不同;
对于cs而言,d/b为0,在32位下,默认操作数为16位,否则为32位;
举例:
1 | push 12 |
上述操作会将esp-4,但当cs的d/b为0时,只会让esp-2;
对于ss而言,d/b为0,在32位下,栈寻址会变为16位,否则为32位;
相当于使用sp寻址(两字节地址),而不是esp;
作用在普通的code段上(ds,es),d/b是0是1都无所谓,没有改变;
DPL
全称:描述权限等级;
代表这个段描述符的权限;一般只有0和3的数值,代表的是0环权限和3环权限;
当CS段和SS段同时DPL为3时,代表程序跑在应用层,同时为0时,代表程序跑在内核层;
补充CPL:当前权限等级,即CS段的DPL;
RPL:在之前的段选择子里出现过,后三位,代表请求权限等级,例如DS为2b,RPL为3,那么就是以3环身份请求访问这段段的内存空间;
在普通数据段下(DS,ES),RPL是无所谓的,没有效果的,但在SS上RPL一定要和DPL,CPL对应相同,不然就会G掉;
对于CS段,RPL也是无所谓的,只需要DPL和CPL对应相同;
调用门
之前在段节里讲的都是一般的代码段和数据段,当s位为1时是如此,但当s位为0时,此时变成系统段,type含义发生变化,具体type内容如下所示:
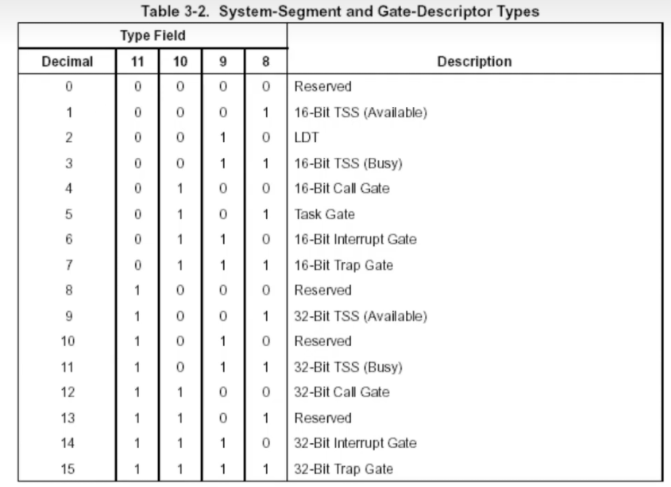
当s为0,type为c时,此时这个段被描述为调用门;
描述符发生变化如下:
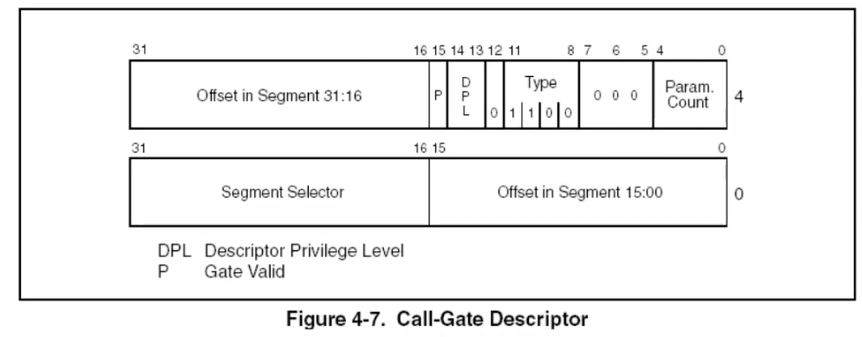
首先,P,DPL,Type的概念不变,后面三个0是默认为0,后面5字节是代表有多少个参数入栈,Segment Selector是新的cs的值,offset则是要去地址的偏移(逻辑地址),加上的base是新给到的cs里面的,而不是当前的cs的base;
进入调入门后,更改cs的同时,会同步更改ss的值为cs的下一个项;
要进入调用门也需要使得DPL和当前cs和ss的DPL值一样;
所以它的意思是,当进入调用门时,进行跨段跳转(call),可提权,如要提权则构造两个段描述符,其DPL为0,分别给到cs和ss就行;
如果提权了,FS寄存器里的值会变化,所以进入r0时,需要保存fs的值(int 3的问题);
进入r0,栈也会发生变化,变成r0的栈,其中存的有返回地址,旧的cs,ss值,旧的栈的esp值;
而r3的原本栈并不会发生改变;
栈结构:
| eip |
|---|
| cs |
| 参数 |
| esp |
| ss |
要使用调用门,则将cs的值改为调用门就行,但是需要更改注册表项:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management的下面两个值:
FeatureSettingsOverrideMask和FeatureSettingsOverride都改为3;
不然使用调用门就会G掉;
一个问题:为什么使用跨段跳跃直接跳到DPL为0的段修改不行呢?
答:DPL需要等于当前CPL!所以需要借助调用门进行提权;
提权小实验
查看gdtr如下:
1 | 1: kd> dq 80b99000 |
可以通过调试发现,应用程序在运行时,CS为1b,SS为23;
分别对应这张表里的3,4项;
可以发现这张表里的1,2项和3,4项是类似的,只是它们的DPL都为0,而3,4项的DPL都为3;
所以可以通过调用门将CS的值改到1项,SS自动设为2项;
构造调用门结构:
1 | 首先我们要跳转的地址为函数test:(401000h 关闭随机化地址) |
将其复制到4b(第9项)位置;
1 | 80b99040 0000f200`0400ffff 0040ec00`000b1000 |
那么只需要通过跨段跳转去访问调用门就行了:
1 |
|
可以了解的到,在test里的操作都是r0级别的,使用的栈也是另一个栈,不是原本进程的栈;
同时只能用call提权,jmp无法提权,原因是当jmp访问调用门时,不会去改cs,ss(机器内部设定);
中断门
除了GDT,还有一个IDT,叫中断表;
中断表中存放的是中断门描述符;
如下是中断门的描述符:
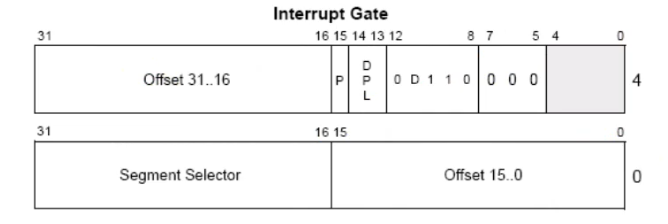
type中的D的意思是,在16位系统中为0,32位往上为1,所以type是e,s还是0;
而其中段选择子,查找的依然是gdt;
偏移指向的地址即为中断处理函数;
通过int index去触发对应idt的表项的中断门,进入中断函数进行处理,同时权限更改为段选择子;
那就可以自拟函数入口,段选择子改作r0级别进行如调用门一样的提权;
注意,此时要使用 iretd 进行返回平衡栈,而不是retf;
iretd实际上是做了一步sti的操作去改写了eflags的if位,同时解除阻塞;
如果直接用retf返回,由于没有改写if位,在内核源码中会进行对这个位的比较,比较不为1就会进入蓝屏;
同时不能直接在r3使用popfd去修改eflags,因为进入后会if自动设置为0;
总结:中断门进入后,会将eflags改为2(if位为0),以我的理解是为了避免中断里面又出中断,所以返回时会恢复if位;
所以在中断门里,其他中断会被阻塞,比如缺页中断;
和中断门类似的陷阱门进入后eflags为202,也就是if位为1;
那实际上中断门进入是清空eflags的VM NT IF TF位,陷阱门少一个IF位;
陷阱门的结构和中断门一样,只是type为f!也是通过ldt进入,int触发;
所以中断门是阻塞的,陷阱门是不阻塞的,原因是中断由外部设备请求,陷阱是程序自发;
在处理函数中的栈结构(r0中的栈)如下:
| eip |
|---|
| cs |
| eflags |
| esp |
| ss |
补充获取表姿势:
32位下四个指令:
sgdt sidt获取,获取的内容是一个6字节结构,前两字节为表长,后4字节为表的地址,r3下即可使用;
lgdt lidt改写,改变表的位置,r0下才可以调用;
INT3_HOOK
一个基于中断门机制的hook小实验;
注意!只有在win32上有效,而且很没有什么实际用处(个人认为,因为会导致其他地方的int3出问题,只有自己进程的有用);
我们知道了对于int调用,实际上就是查idt表;
那么int3实际上调用的就是idt表第三项的函数,同时改段属性;
对于INT3_HOOK的本质,就是不去更改描述符中的函数地址,而去改描述符里的段属性;
使得进入int3调用的时候,依然使用原地址寻址,但是加上我们自己构造的base值,跳转到相应的hook函数,再jmp回原本的int3地址;
这样做的好处?根据我的理解实际上在做的时候,应该是自己构造一个伪gdt,而不是去动int3的段选择子;
这样才能保证ldt原封不动没去修改,被检测到hook的可能降低;
但是请注意,由于intel的CPU有两个个特性:流水线和预测,根据我的理解,它会把取地址,译码,取数据,以及预测后续地址分开进行;
那么会出现一种情况:当我们跳转到hook函数时,这个时候的cs段的base不是0,那么在后续预测时取到新的地址块(一块一块取地址,一一条一条这么寻址效率太低),它的寻址方式就会用那个地方的eip + base,相当于取到的代码都飞远了,译码也是用的这些远处的代码,自然会崩溃,像是有一个缓冲代码区,会把预测的代码提前取到缓冲区进行预测,取数据,只有进行大跳转的时候,或者到了该取新地址块的数据的时候,这个缓冲区才会刷新,刷新的同时会进行寻址;
所以当我们进入hook函数的时候,就应该直接跨段跳转走,跨到base为0的段上去正确执行我们的代码;
思路是:
- 构造gdt一个新的描述符属性为我们自己定义的段去进行hook函数的跳转;
- 那实际上进入r0,需要ss段一起更改,所以还需要写一个ss段的描述符在新描述符的后面;
- 修改int3处的段选择子为新段;
- 进入中断门后进行cs跨段跳转为base0;
- hook功能实现;
- 跳转回原int3执行;
获取gdt和idt:
1 | 1: kd> r gdtr |
我会选择修改int3描述符为:
1 | int3:83e4ee00`0008c800 -> 83e4ee00`0060c800 |
并在gdt 60的地方,也就是807d2c80的地方,写上cs段描述符和ss段描述符(r0权限):
1 | 7ccf9b5b`4800ffff 00cf9300`0000ffff |
这里base设定为了7c5b4800,因为7c5b4800+83e4c800 = 401000,是我们hook函数的地址;
使用windbg查找内核函数DbgPrint,我们在实现功能处打印一个字符串,以表示hook成功:
1 | 0: kd> u nt!DbgPrint |
拿到内核函数地址:0x83e09271
接下来就是代码实现了,当我们修改完gdt和idt之后,利用进程去实现hook:
1 | //vs2008模板 |
当激活int3时,就会进入myHook函数,之后进行打印字符串,然后转入真正的int3执行它的代码;
需要注意的是,windbg并不会显示打印出来的字符,需要使用
1 | .ofilter "内容" |
去设置过滤规则,它是完全匹配的,少一个字节都不给你回显(回车键\x0a)!
设置好之后,一定要去生成好的文件执行,不要通过vs的调试模块执行,为什么呢?
因为调试模块执行会给我们自动下int3断点,但是它的进程的401000不是一个有效的函数,所以会直接蓝屏!
执行的效果如图:
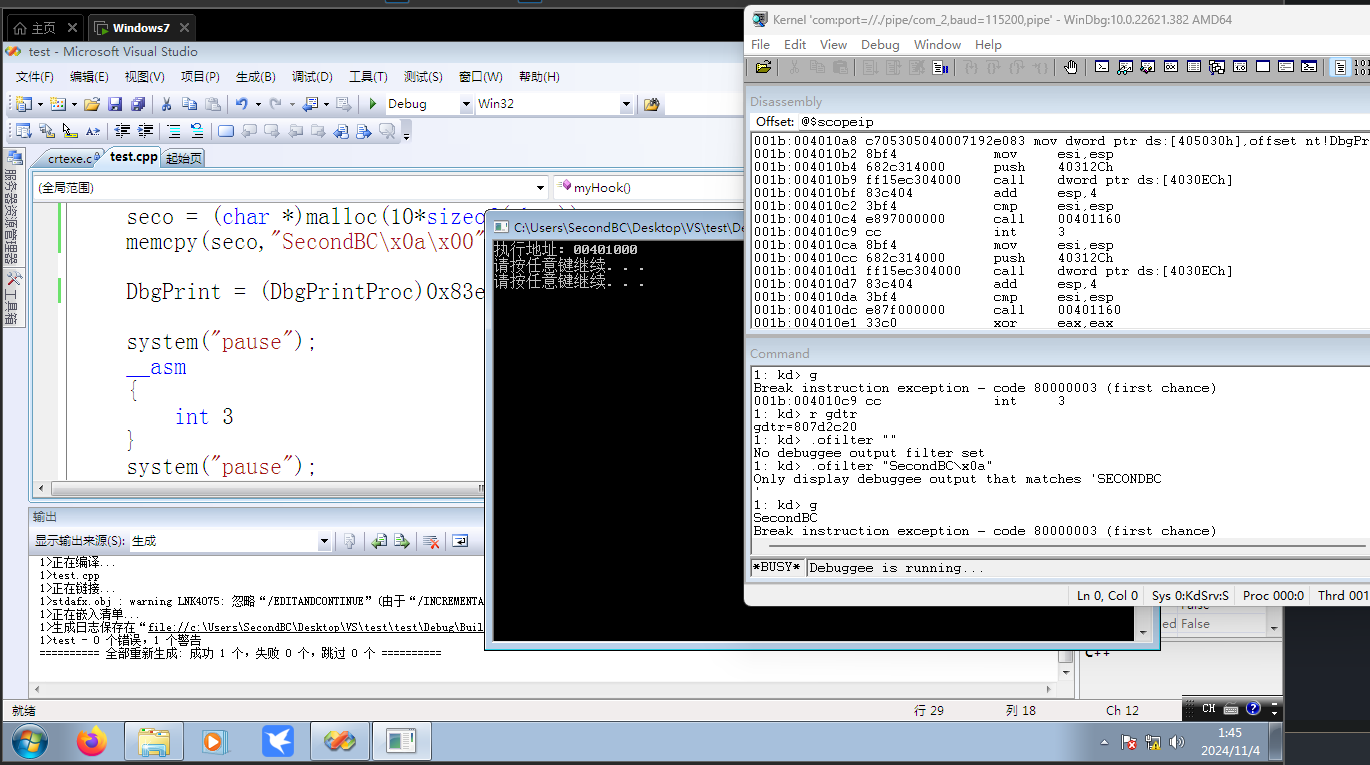
可以看到windbg成功带出字符串,证明hook成功;
纠错:但经过这个实验可以发现ss实际上还是被设置为了10,也就是默认的r0 ss段!并不是设定cs段的后一项?
实际上是因为32位系统会取tr任务段里面的ss保存值,进行r0切换,对于syscall一类的系统调用会是cs的后一项值;
任务段&门
在64位中,任务段用的特别少,几乎不用做其原本功能;
补充windbg操作指令:
dg 0000h 解析段选择子选择的段描述符;
dt 模块!名称(可搭配正则表达) 查找符号对应地址;
!process 0 0,进行遍历操作系统上的所有进程;
在寄存器中,也有一个寄存器专门存放任务段,在windbg里面叫做 tr ;
存放的则是任务段的段选择子;
任务段的功能则是保存任务段结构,切换任务段则切换任务段结构;
如下为任务段结构:
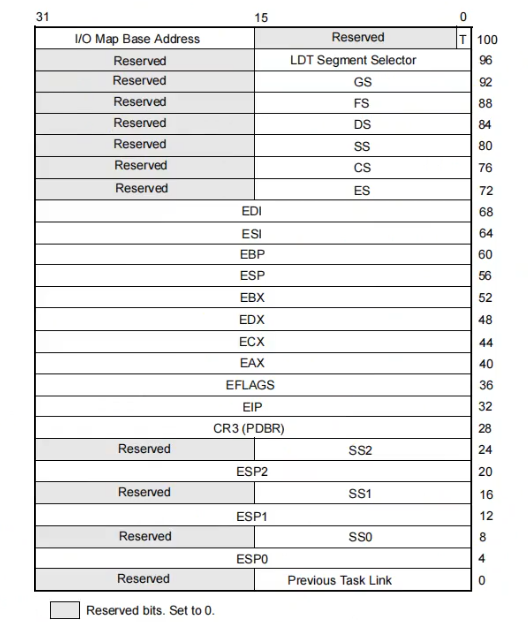
实际上就是切换寄存器环境,所以一个任务,相当于一个线程;
但是操作系统为了不和CPU硬件的功能设计捆绑在一起,所以虚拟了线程的概念,而没有实际直接运用任务的概念;
Previous Task Link存放的是旧的任务段选择子的值,ESP0,ESP1的意思是0环的栈,1环的栈;
每个环都有不同的栈;
LDT指的是LDT的段选择子;
任务段描述符:

其中就存放了任务段结构的地址(base属性),type里的b,指的是busy,如果是可用的(available)则是0,如果是正在用的(busy),则是1;
任务段也是放在gdt表,使用call或者jmp都可以跨段并切换环境(任务段结构),同时jmp也只能用在这里提权;
用这种方法切换任务,会使得当前eflags的NT位(嵌套任务)置1;
iretd执行的时候会先检测NT位,如果为0,则按照栈存方式恢复寄存器;
如果是1,会按照Previous Task Link保存的内容进行恢复返回;
之前的调用门,中断门进入的时候,实际上就是在当前任务段结构的esp0,和ss0上进行找值更改,但是并不会改变tr;
任务门描述符如下:
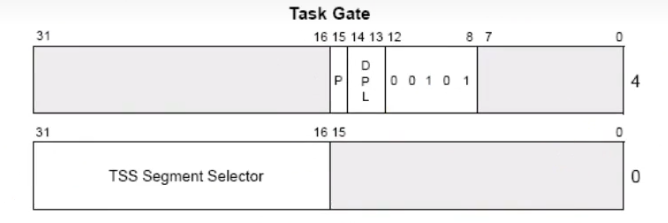
它只有一个属性:任务段选择子;P DPL S也是e(1110),type为5;
在32位下,一般放在int8的位置(idt表),通过int激活进入门,效果和call任务段一样的,都是切换寄存器环境;
但有一点,因为它是在中断表里的,所以会有中断门的性质,比如VM IF TF的清空,但会把NT位置1,原因前面说过了;
页
引入和介绍
win32下的分页模式一般有两种,一种为101012模式,一种为29912模式;
后者有个特征便是进程的CR3是按20h隔开的,win7默认就是;
要在win7上配置101012模式分页的步骤如下:
首先也是创建一个新的引导,步骤如环境节里所述;
之后用管理员权限打开cmd,输入如下指令:
1 | bcdedit /set pae ForceDisable #强制关闭pae |
之后查看cr3以确认是否配置环境成功;
在system32目录下,有两个内核文件:
ntkrnlpa.exe和ntoskrnl.exe;在system32/driver里的驱动文件,其模块就包含有ntoskrnl;
这两个文件是分页用到的文件,前者对应29912,后者对应101012;
模块不会包含ntkrnlpa,但是如果模式是29912,依然用的是ntkrnlpa里面的内容,就和kernel32和kernelbase的关系类似;
已知保护模式下用的是虚拟地址,如何得到物理地址?
页表寻址
要使用到操作系统课上讲的页表机制;
101012模式指的就是10位 10位 12位;
虚拟地址32位按照上述规则进行划分,12位代表页内偏移,中间10位代表页表项(PTE),高10位代表页目录项(PDE);
实际上可以理解为两级页表,为了实现页表的切入切出和离散存储(因为页表也比较大),所以才有的二级页表(页目录);
每个进程都有一个cr3寄存器,里面存的值是一个物理地址;
这个物理内存就是二级页表,通过这个二级页表进行虚拟地址的查询方式,进而获得虚拟地址对应的物理地址;
页表存的都是指针,但是后12位代表属性,不做为地址使用;
注意,在windbg里面查看物理地址,需要带感叹号!dd;
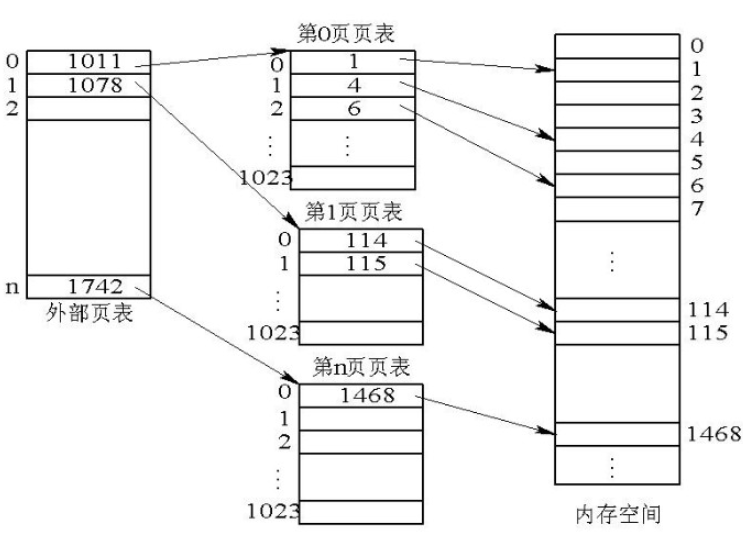
具体寻址算法为:
一级页表地址 = ((DWORD*)cr3值(二级页表))[虚拟地址高10位] (高10位是个索引,不是偏移)
对应内存块地址 = ((DWORD*)一级页表)[虚拟地址中10位] (中10位代表页号,也是索引)
真实物理地址 = 内存块地址 + 页内偏移
需要注意的是,101012分页模式页表存储的直接就是地址,不是内存块号,不要换算;
上面就可以解释,为什么同样的40W地址能拿到不同的内存内容,因为cr3(二级页表)不一样啊,对应的一级页表也不一样;
对于CPU而言,里面有如下内容:MMU单元,TLB快表,页表缓存,L1,L2,L3缓存;
MMU单元就是负责页表寻址的,其基本功能就是一个输入cr3和虚拟地址输出一个数据的函数;
一开始寻址的时候会直接拿高20位去TLB里面找缓存,如果找到了,就会得到一个内存块号,接着拿到L1~3中去继续找对应存储数据内容,找不到就开始拆虚拟地址;
当把高10位拆出去之后,把中10位(一级页号)拿到页表缓存中去找,也是一个道理,如果找到了,就会得到一个内存块号,接着拿到L1~3中去继续找对应存储数据内容,找不到就继续拆虚拟地址;
当拆到底以后,计算出物理页(内存块),就会拿到L1~L3去找,还找不到?
还找不到就计算板卡地址,到内存条上去寻址;
当取到数据以后,会把数据对应的内存块,一级页号,二级页号,依次写回缓存中去,方便下次快速查找;
对于L1~L3的关系,则是经过一段指令周期以后,L1往L2写内容,L2往L3写内容,L3往内存条写内容,L1则是由内存上取到数据以后进行写回;
实际上L缓存的结构像是一个二维数组;
假设L1~L3属性如下:
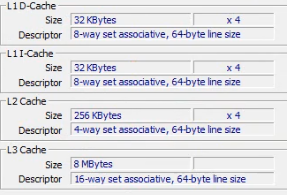
实际上L1分成了两部分,一部分是D(数据),一部分是I(指令);
以L2作为例子,总大小为256KB,每一行有64B,相当于有(256*1024)/64 = 4096行;
L2有4路,代表的意思是将4096分成四份,每一份拥有4096 /4 = 1024行;
相当于每一份拥有1024*64 = 64KB,在CPU内部的算法将L2内容写回L1时,或者写到L3时就是按照64KB为一次来的(分块写);
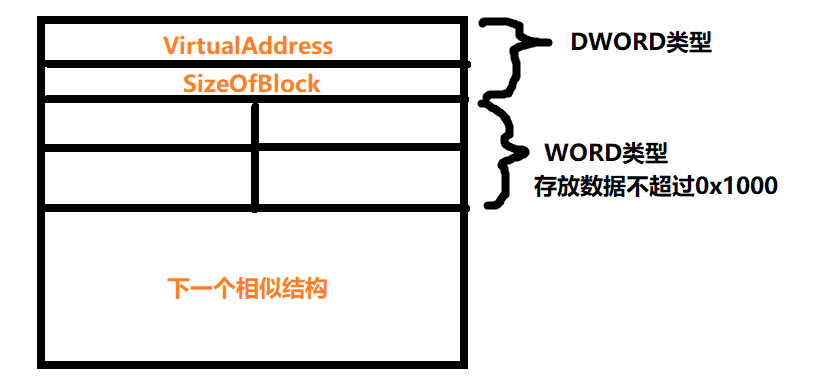
页表项属性
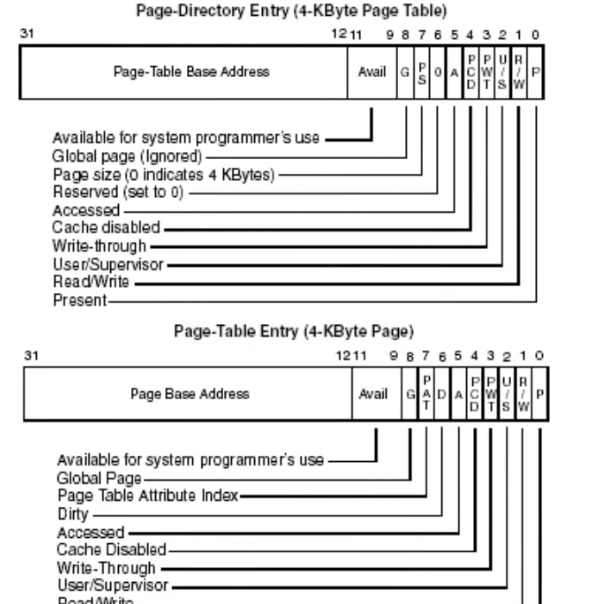
PDE和PTE分别对应二级页表,一级页表,他们的后12位都是属性值,因为它们都按1000h对齐,所以后12位空闲可用;
p,有效位,为0是无效;
R/W,读写位,为0只读,为1可写;
U/S,权限位,为1是r3,为0是r0,和之前讲到的s一样;
PWT,PCD,PAT与缓存相关;
A,访问位,访问过就置1;
D位是修改位,被写过就置1,二级页表(PDE)的始终为0;
PDE的PS位是大页位;
G,全局页;
avail,给操作系统预留;
补充知识点:
就算是这里算出来的物理地址,其实都只是L1~L3缓存的一个索引,并不是内存条上的地址,内存条上的地址叫板卡地址;
实际上访问L1,L2,L3也是通过访问其每一行的哈希值进行读写的,并不会直接使用物理地址;
虚拟内存换进换出的操作,使得没有使用的新分配内存空间不会获得物理页,也就没有页表项,内存的释放其实也是对页表项的释放;
当程序访问到页表时发生缺页中断,自行修复,恢复页表项和对应物理页(比如memset函数);
挂页实验
我们已然知晓页的机制,那么是否可以替换别的进程的0地址(虚拟地址)为我们自己分配的页地址(物理地址),以执行我们的壳代码呢?
答案是可以的,在这个实验中修改目标进程的二级页表依然会用到windbg,目前还无法脱离windbg进行修改;
同时会用到OpenProcess查找目标进程,CreateRemoteThread创建远程线程去主动执行壳代码;
补充个小知识点:堆区不属于任何一个段,而且在现代操作系统中,保护模式下,段其实都是一个概念,没有真的用到偏移计算这种东西,只是一个权限划分罢了,基本上都是靠分页机制来进行对内存权限的管理和分配,又因为101012分页模式,导致一个问题则是什么页都可以有执行的权限;
代码脚本如下:
1 | // test.cpp : 定义控制台应用程序的入口点。 |
首先启动这个脚本,它会停到第二步,这个时候mem的地址依然打印出,且每次打印的页内偏移都是4b0;
此时远程线程的虚拟地址为4b0,第一次和第二次页表都是0项,所以到calc进程的二级页表0项里面的0项给改成通过mem找到的物理页即可;
又因为偏移相同,所以可以通过4b0虚拟地址找到相同的内存空间;
再次回车执行远程线程,此时可以发现calc弹窗了;相当于calc进程执行了我们这个进程的一个函数!
页管理
对于101012模式,一个进程有1024(2的十次方)个PDE和PTE(二级页表项和一级页表项),每一项都是存放4字节指针的,所以一个进程的页表一共就有4MB大小;
又因为高地址2G共享,每个进程的页表有2MB都一样;
同时在虚拟内存的高2个G内存中,是内核内存,其中有4MB就是专门用来管理当前进程的页表的;
在ntoskrnl文件中的一些操作就是对这个区域展开的;
在101012模式下,操作系统设定的当前进程PDT(二级页表)位于 c0300000,PTT(一级页表)位于 c0000000(定死了,它们永远都是这个);
在ntoskrnl文件中进行物理寻址的时候,利用的则是这两个基址,因为ntoskrnl文件不能直接使用物理地址,也需要虚拟地址;
因为ntoskrnl文件也是一个软件,尽管它是专门用于页表处理的;
当操作系统本身进行页处理的时候,会通过这两个基址进行CPU intel架构的计算,从而拿到物理页地址(映射关系);
一个技巧:
- 由于操作系统使用了虚拟地址来管理两个页表,那么可以通过实际CPU intel规定的页表寻址方法对 c0300000进行寻址(这个虚拟地址是否和cr3二级页表物理地址一一对应呢?),拿到的就肯定是cr3的值,也就是PDT(二级页表)对应的物理地址;
- 对c0300000拆分,则是 300 300 000;
- 已知当前进程的二级页表基址为c0300000,那么c0300000 + 300*4 = c0300c00,这个地方存的值实际上就是cr3;
- 拿到这个值再次运算! cr3 + 300*4 = c0300c00(虚拟地址依然是这个);
- 取页内偏移: c0300c00+0 = c0300c00;
- 所以 c0300c00 存的就是当前进程的cr3值!
- 这样就可以不访问cr3而获取cr3的值(32位下绕过VT);
如图所示:

这是一个环; 101012模式下,cr3+c00即可拿到本身;
29912模式
101012模式是位于32根地址总线的分页模式产物;
对于内存的不够使用,CPU架构引出了36根地址总线的分页模式:29912,使用的技术叫pae技术;
它的地址继承了原本的4字节长度地址,线性地址没有突破,还是32位;
但是由于物理内存(不是内存条)大小此时是2的36次方,64G,所以二级页表,一级页表的表项有了增多;
原先的表项是4个字节,一个页内存1024项,现在的表项是8个字节,一个页内存512项;
相当于也是管理4G内存,但是使用的页表总计为:
$$
4512512*8 = 8MB
$$
总共8MB;
分页模式相当于多了一个页表,变成了三级;
2 9 9 12的模式,计算规则同上,只不过项索引需要乘8,因为每项占8字节;
在29912模式下,虚拟基址是c0600000(PDT二级页表)和c0000000(PTT一级页表),可以从ntkrnlpa.exe中获取;
在进程内,只需要使用这两张表,不需要用到第三级页表,第三级页表的表项属性不影响最终的结果,依然是看两级,一级的页表项属性;
但是从cr3开始找是算三级页表的;
多出来的内存不是用于进程,而是供给键盘,等usb设备使用;
由于101012模式下,所有内存都有可执行权;
所以在29912以后,都在页属性(PDE,PTE结构)的最高位位置,新设了一位XD(NX)来进行执行权的约束,为1不可执行;
在此模式下,malloc申请的空间就不可以直接执行了;
这是DEP保护的本质;
缓存
在页表属性的时候,提到了三个位和缓存有关:PWT,PCD,PAT;
概念:
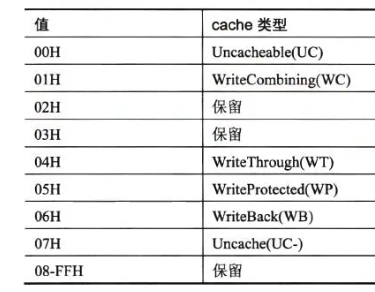
首先要有的理解是,CPU读数据写数据都是优先读写缓存的(L1,L2,L3);
同时,一行64B,作为缓存行;
0 -> 无缓存,直接从内存条拿数据;
1 -> 写合并,对于写这一过程,取L1缓存行没取到,取L2取到了,那么写到L2的同时,给L1添加相同缓存行,一次4个地址(intel);
6 -> 回写,根据计数器被写回到内存条(先写回L1);
4 -> 直写,写到缓存后,同时同步到主存(从L1,L2,L3一路同步过去);
7 -> 弱无缓存;
5 -> 写保护,只读,不可写;
利用写合并的特性,可以一定程度上提升CPU效率(比如一个特别大的循环里只一次性赋值4个值,可以多循环几次,这样比循环一次赋多值更快!)(疑似无效了?);
写保护和 R/W 位实际上是一个东西;
对于只读的页属性有一个有意思的地方,这里先给出前置知识:
虚拟地址管理(VAD)会给出当前虚拟地址所拥有的属性(保护模式下的段概念);
这个属性里也有RWE,同时有一个写时拷贝的属性;
同一路径同一名称的dll被不同exe加载,使用的物理页一样,虚拟地址不一样而已;
使用VirtualProtect改的属性实际上是VAD指向的属性,页属性不做变化;
当VAD的属性是可写的时候,而指向的物理页的R/W或者写保护位是不可写的时候,操作系统触发页异常,此时会查看VAD里面的写时拷贝属性,如果为1(写时可拷贝),那么就进行异常处理:将物理页分成两份,并给写到的物理页属性变为可写,此时两份dll内存才分开;
写时拷贝的意义在于只有改变时才进行隔离,因为不改变时,两份相同的没有意义,只用一份即可,所以直观看起来,每个进程的模块也是独立的,实则不然;
PAT: 页属性表,当此位为1时,该页用于管理缓存的属性;
PCD: 页缓存关闭,当此位为1时,不用缓存;
PWT: 页直写,为1就是直写模式(适用于多媒体实时更新);
TLB
一般分两种类型 ITLB,DTLB;
I是指令,D是数据,它们的TLB不是同一个,是分开的;
这两类又细分小页(4KB)TLB和大页(2MB,4MB)TLB;
大页的概念:由PDE直接寻址,即二级页表指向的直接就是一个大的页面,PDE.ps属性为1;
32位下,TLB内部存放的格式大概如图:
| 虚拟页帧 | 物理页帧 | 属性 | 次数 |
|---|
页帧的概念就是不加页内偏移的其余部分;
我们之前说过,TLB快表的存在的意义就是加速物理地址访问,省去映射过程,省去内存中的页表结构访问过程;
如何证明它是存在的呢?正常而言,它的过程和效果就和映射,查看页表一样,对于我们人来说是不可见的;
但接下来这个实验可以证明TLB真实存在;
我们分配两个地址空间,分别是a和b的内容,然后我们分别把这两个地址挂到虚拟0地址;
接下来分别访问两次0地址,如果两次访问结果内容相同,就说明是有TLB存在的;
因为访问过一次以后,它会把对应TLB关系写入TLB内,第二次访问它直接拿0地址去TLB寻址返回对应的物理页帧,而不再重新映射一遍;
我们这两次访问要足够快,不然TLB就把记录给刷掉了;
所以选择使用中断门进行手动修改和访问,代码如下:
1 | // test.cpp : 定义控制台应用程序的入口点。 |
实验结果如下:
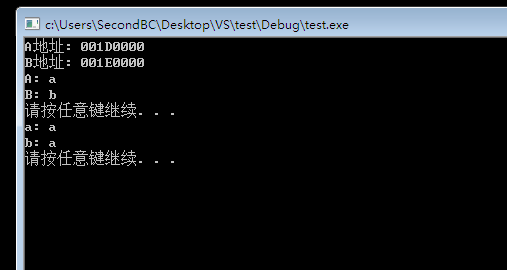
这说明TLB确实存在,不信可以仔细看看代码;
在指令中,有一个指令 [invlpg 地址],指定刷掉TLB中的对应虚拟地址;
控制寄存器
32位如图(64位也有它们):
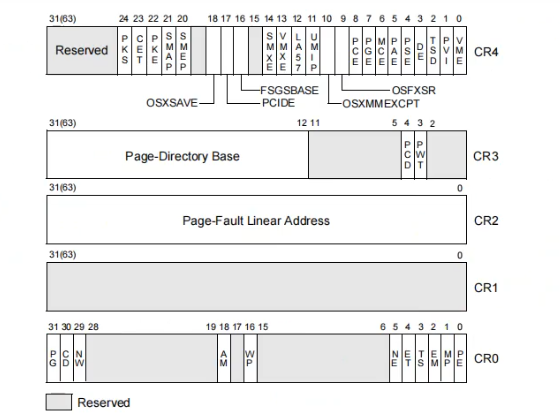
CR1是保留寄存器没有使用;
CR2存放的是页异常虚拟地址,用于告知14号中断是哪个线性地址出了异常,中断调用没有形参;
CR3存放页表基址,以及标记该进程的缓存属性;
CR0:
PG是页模式开启,PE是段模式开启,在保护模式下默认都是1;
EM,MP,NE,ET是和数学,浮点数,错误相关,不太重要;
TS是任务段,在任务段内TS置为1;
CD置一,那么全部没有缓存,是缓存总开关,NW置一,所有都不直写;
WP,保护写,写权限的总开关,置为0强行写任意页;
AM,r3环境下的对齐,64位下,为1那么CR4里面的SMAP,SMEP生效;
CR4:
VME,开启虚拟8086模式;
PVI,开启虚拟8086模式下的模拟中断;
TSD,如果为1,r3可以调用rdtsc指令,否则报错;
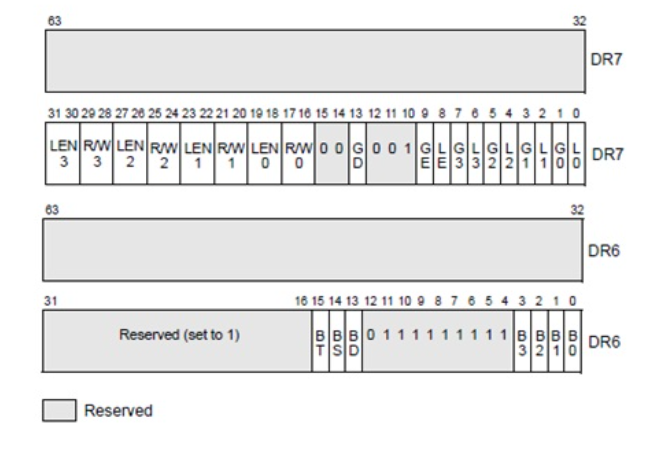
DE,如果为1,DR4=DR6 DR5=DR7,否则访问DR5,DR4异常(调试寄存器);
PSE,如果为1,大页有效,大页总开关;
PAE,如果为1,那么29912,否则101012;
MCE,机器检查中断(0x12中断)有效位;
PGE,如果为1,页的G位有效,否则无效;
PCE,监控事件开关;
VMXE,如果为1,开启VT;
SMXE,如果为1,开启上帝模式;
OSFXSR,OSXMMEXCPT,UMIP,LA57,OSXSAVE与浮点相关;
FSGSBASE,FS可以不通过段解析拆分,rdmsr指令直接获取fs基址;
PCIDE,每个进程的CR3是否有缓存;
SMEP,SMAP -> super mode (execute/access),如果为1,r0不可以执行和访问r3;
CET, 无用;
PKS,PKE,是否加密页表;