题目附件:https://pan.baidu.com/s/1qEbEZ_xdS33hOiExvLR7ng?pwd=3457
一个exe程序,直接拖到ida里,发现没有main,很混乱,直接猜测上了自解密 + 混淆花指令;
根本看不到伪代码,硬啃汇编罢;
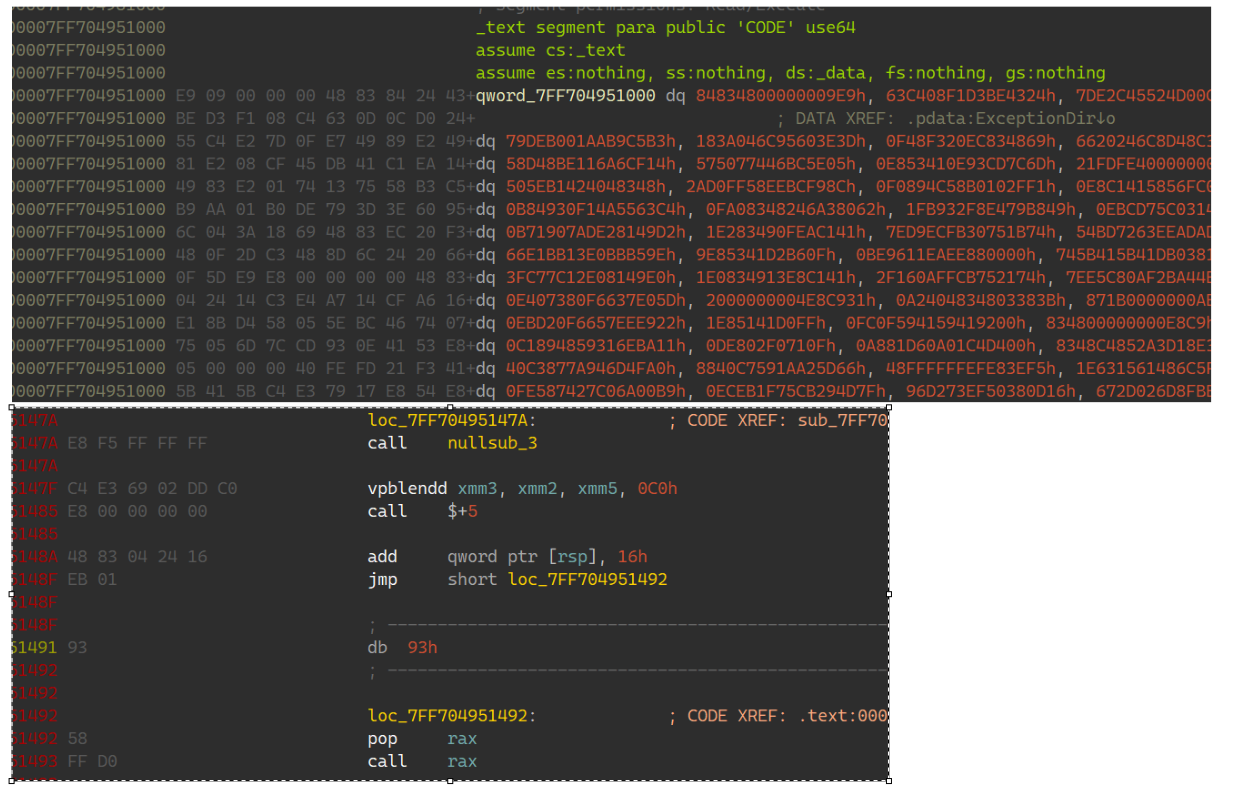
不打算修,太多了,直接调,函数列表搜索scan,可以拿到库函数:
?scan_optional_field_width@?$format_string_parser@D@__crt_stdio_input@@AEAA_NXZ
在这个函数里打上断点,可以在输入内容的时候断下,然后一层一层的往上层函数断点测试:
可以找到最终的scanf调用实际上使用了下面这个函数:
??$?RV_lambda_a81aa23bb2c9577c1e55b9d0b57d9de4_@@AEAV_lambda_9a20e10065b92b5193c3597a66cba9d4_@@V_lambda_cb3a421ff86d8a5f008440ee6b28fa9c_@@@?$__crt_seh_guarded_call@H@@QEAAH$$QEAV_lambda_a81aa23bb2c9577c1e55b9d0b57d9de4_@@AEAV_lambda_9a20e10065b92b5193c3597a66cba9d4_@@$$QEAV_lambda_cb3a421ff86d8a5f008440ee6b28fa9c_@@@Z_1
也是一个库函数,接着这个函数往下走,可以走到一个神奇的地方,我称之为中转站,也是找到虚拟机的特征,操作码一类的东西:

这个rax实际上就是一个操作码,每次都有不同的功能,在前几次调试测试会发现,第一次调用call之后,就会打印wrong flag;
而当rip在这个地方的时候往栈上看,能发现我们输入的内容:
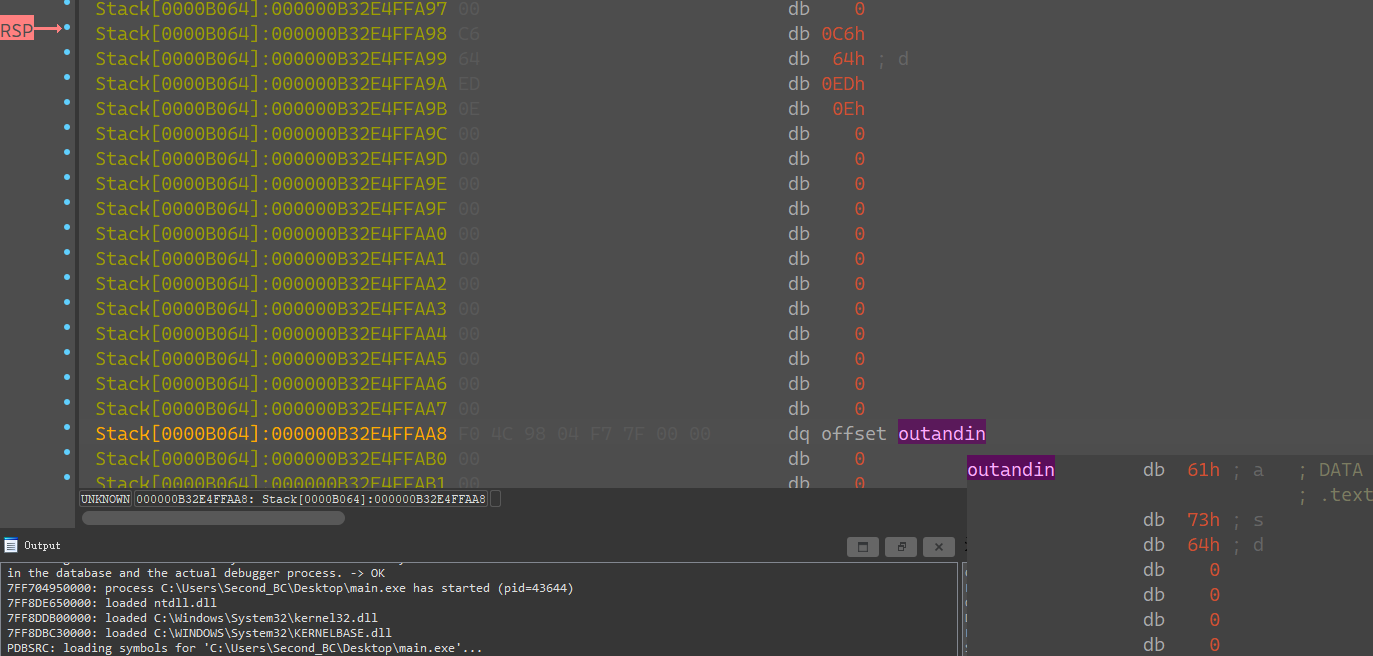
对着我们输入的地址按x查看引用能找到一个地方,调过去能发现这是第一次call会执行的,再次调试能够知道实际上是在调用strlen函数,它将strlen给到rax,然后call rax,过了中转站之后第二次call就会打印wrong flag:
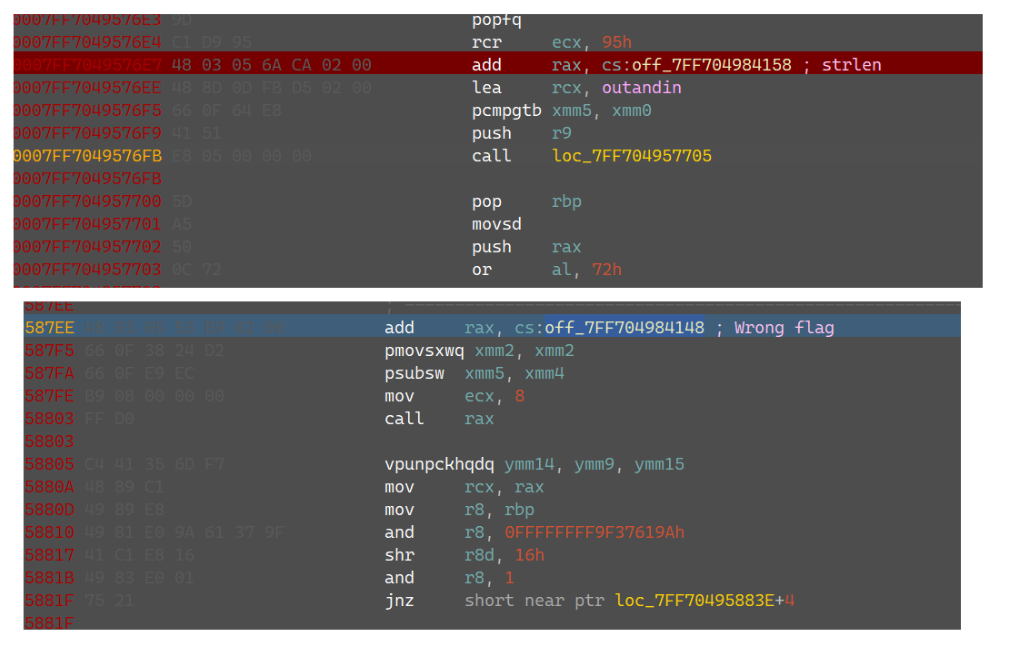
对着strlen再继续跟下去会得知flag长度是56;
如果长度是正确的,第一次call完之后,剩下的call就开始循环了,貌似在操作输入的字符串;
通过每三次call,可以发现它是一个动作,每三次rdx都会加2,当加到70h之后变成新的循环;
实际上也就是以56为一个循环,一共要循环两次,但是调试的时候发现第一次循环没有对输入的内容做修改,而第二次循环会对输入的内容替换为用7F去减去它本身的值(通过观察栈上的值);
这56长度的循环结束之后,会有一个短循环,一共call 26次,第25次就会输出wrong flag,第26次进入结束程序;
通过调试可以发现,这26次里面,在对输入的内容进行分组加密,每8字节为一组,应该是电码本模式,因为56个a加密的东西分组的很明显:
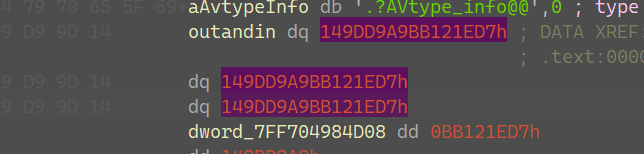
对8个字节的分组加密部分也是3次call为一个动作,一共执行21次,把7个分组都加密完,剩下的4次call很可能就是用来进行判断的;
跟踪剩下的call可以发现很难看,很多都是没用的跳转,所以结合着打上内存断点,可以找到如下内容:

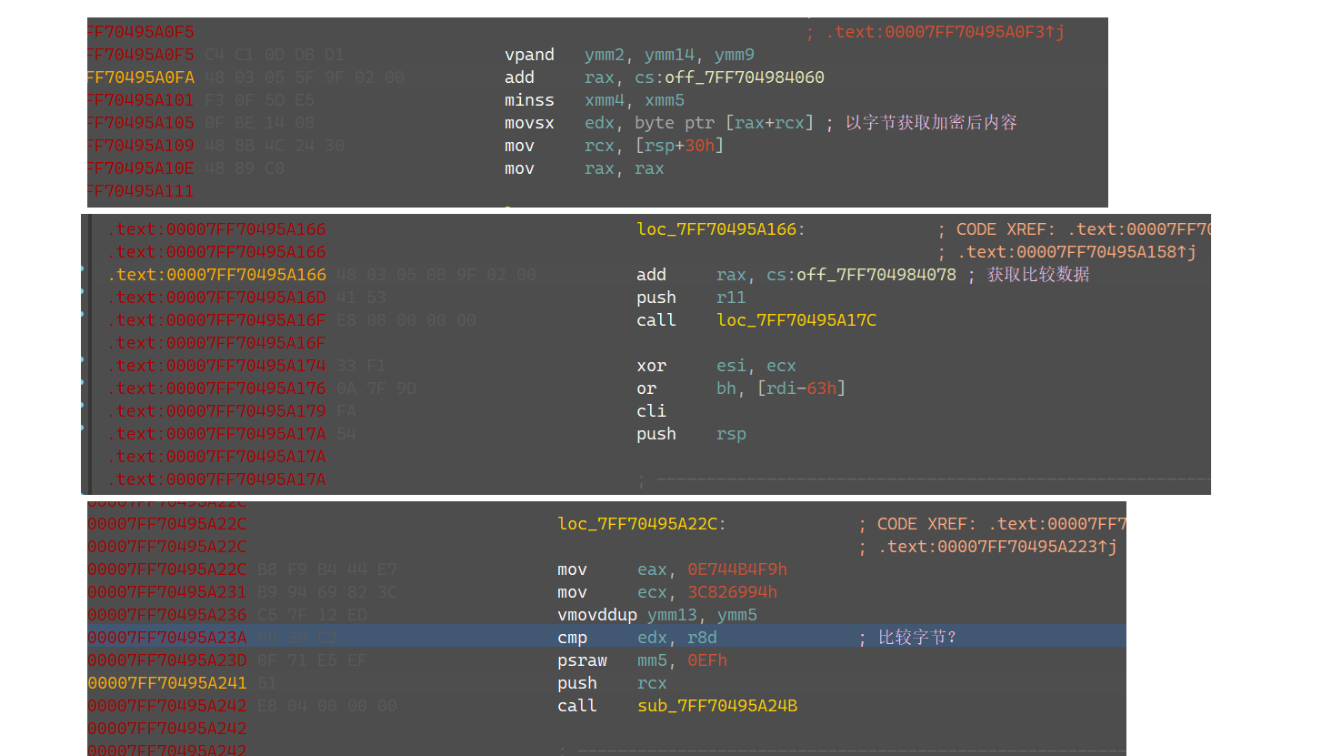
它会依次获取加密后的输入数据,以及比较数据?这个比较数据每次都在变化,然后进行比较,通过调试改值,可以一路改下去,然后就能够使得程序输出right flag的字符串,打到这个时候其实已经就很有信心能出了;
为什么直接引用outandin地方的地址不能直接x获取到这些被引用的地方呢?
是因为这个混淆做了一个表,它每次要获取地址的时候,都是用代码段上的立即数去加或者减这个表里的无意义的数据,得到一个可用的地址,这样就防止了地址引用的查询,但是还是逃不过内存断点;
使用如下ida的python脚本进行更改比对值且输出比较内容:
1 | ea=get_reg_value("r8") |
对打印的内容进行整理拿到如下比较hex:
1 | BE 44 7B 02 BA 95 4B 8C E3 A8 F1 90 FB CD A4 3C 2F EE 9E 68 79 AA 6D ED 85 B0 77 2F 27 3F 41 FF 1F C1 CF 43 AA 00 AC FA 71 43 57 09 51 BA F7 B2 67 96 52 47 A0 50 40 C7 |
现在要做的就是查看分组加密算法了,回到当时加密的部分,一步一步的跟踪看过去,发现程序会去操作两个寄存器:
1 | 算法逻辑: |
那最终经过一段又臭又长的小丑代码膨胀之后,你会拿到eax会变成 0x9e3779b9;
包是tea里面的delta,弟弟;
通过进一步调试我能拿到如下栈帧内容:
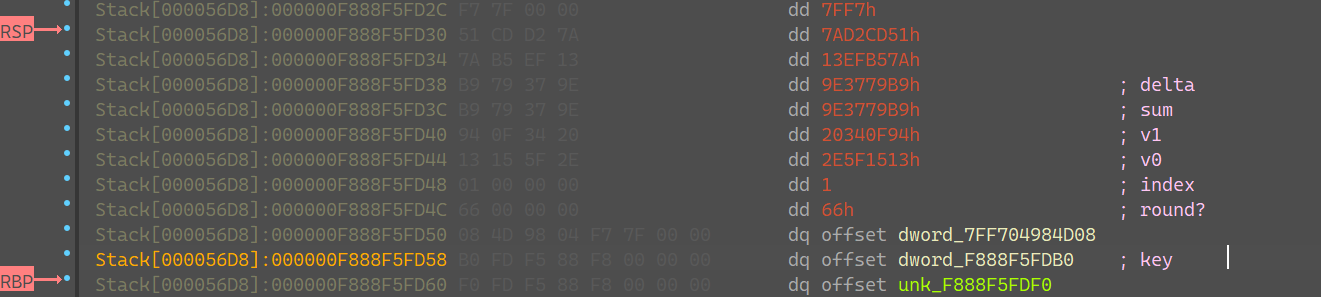
能够拿到key和轮次,那么直接把三个tea都拿来试,试完可以发现是xtea(不是tea和xxtea);
写逆运算,直接拿到不可见字符,太棒了,我逐渐理解一切;
思考是否是因为有反调试在搞我,于是尝试用ida附加进程,发现附加不上,很大可能;
拿CE进行附加调试,可以发现最终的比较数据发生了变化,同时我们输入计算的结果也发生了变化(千万别用其他算法搞我):
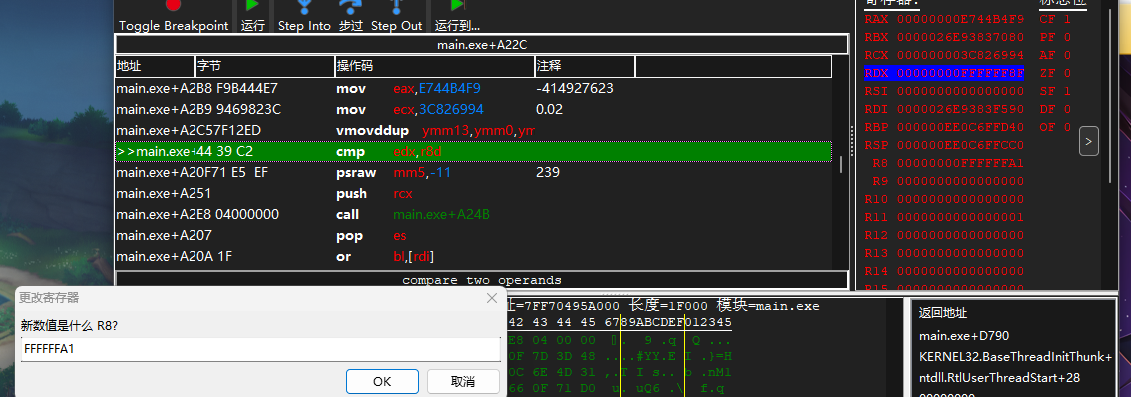
第一个思路是找idata段(iat表)用到了反调试的哪些函数,可以找到疑似的如下:
1 | .idata:00007FF704979060 20 7F B1 DD F8 7F 00 00 IsDebuggerPresent |
对其进行x引用反查并下断点,能够发现不是他们的原因(不会断下来);
接着对ida里进行search,搜索字节块,直接搜索hex 60 (对于静态反调试而言,PEB结构很重要,32位是fs:30 64位是gs:60)
然后在搜索的结果里ctrl+f筛选gs,果然给找到了:
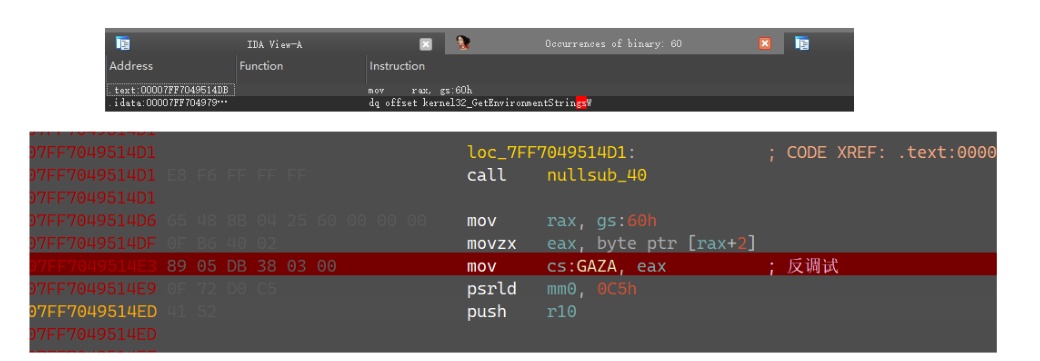
之后在这里给下个断点,ida调试一启动程序就到这里来,先把eax改成0,然后把上面一条句子改成xor eax,eax nop nop;
就可以不用管这个地方了;
之后还是一样的调试,能够发现第一轮56长度循环的时候对输入做改动了,对输入的每个字节进行加40h,第二轮循环还是老样子,分组tea也是老样子(还好没变,变了我要把出题人给草草了),然后比较的数据也变了,内容就是ce里面的,说明ce附加调试是正确的数据,用之前的方法再提一遍数据:
1 | a1 e3 51 98 86 56 76 49 6f 6b 2b 81 cf ce 12 96 a2 70 35 3c 31 62 5c f1 fa 77 6b aa 9e 6d 05 be e8 24 a4 f8 db 23 3a 0b 16 20 cc 03 ad b5 2b a9 34 9f 78 1d 2e b9 f9 9e |
这次数据就是正确的了;
反思:拿到怪玩意儿先找反调试,不然后期恶心死我;
之后写脚本进行flag获取:
1 |
|
最后拿到flag:flag{u_ar3_re@11y_g00d_@t_011vm_de0bf_and_anti_debugger}
草草了,ollvm,还是第一次见混淆之后的程序,太抽象了,有一种vmp的美,给我搞了一天,难绷;
根据flag可以知道有一个deobf的工具应该可以有效去除ollvm的混淆,之后可以研究来看看;