介绍: angr是一款针对于CTF的工具,说实话并不觉的它对复杂的逆向程序有什么更优的作用;
它的常用功能则是根据使用者自己写的求解约束,附加在程序上计算如何输入进而求出得到的效果来获取正确输入,类似一款爆破计算器;
如何下载呢? 终端输入 -> pip install angr;
具体的练习上手题则需要去GitHub上搜寻:https://github.com/jakespringer/angr_ctf;
主要内容: Project -> 附加的程序,在angr里叫项目;
State -> 状态,模拟的PC所指;
Simulation -> 模拟空间,为状态不断更新使程序执行指令,模拟运行所提供空间;
Explore -> 模拟运行程序并附加内容;
这4个便是angr使用的主要内容,基本解题脚本都离不开这4个,接下来就用GitHub上的题目来一一解释使用方法,以及进阶内容;
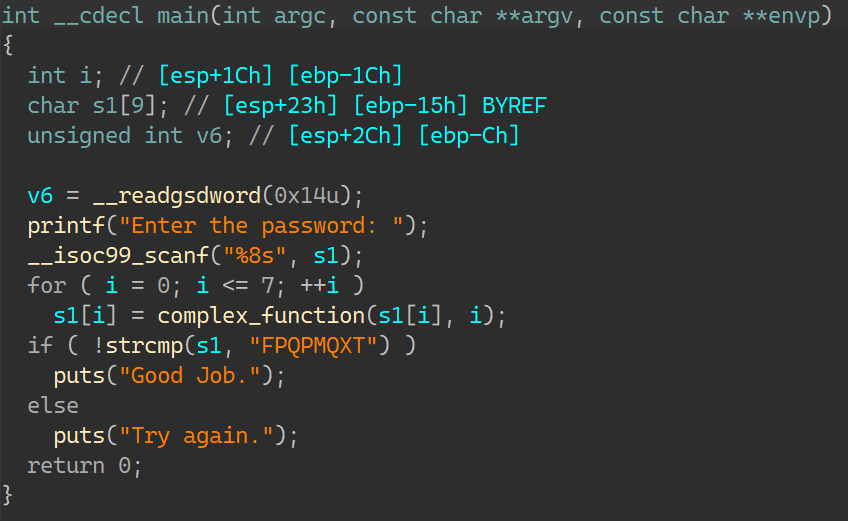
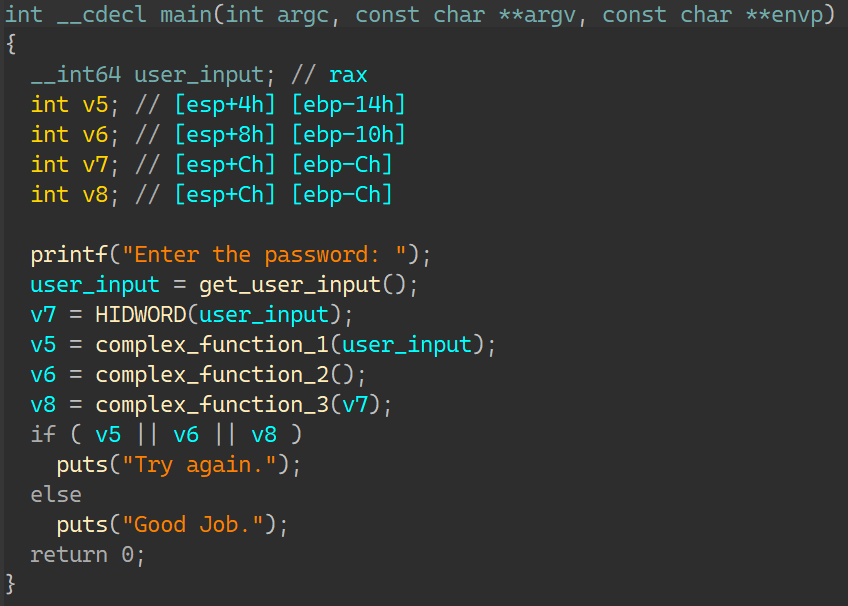
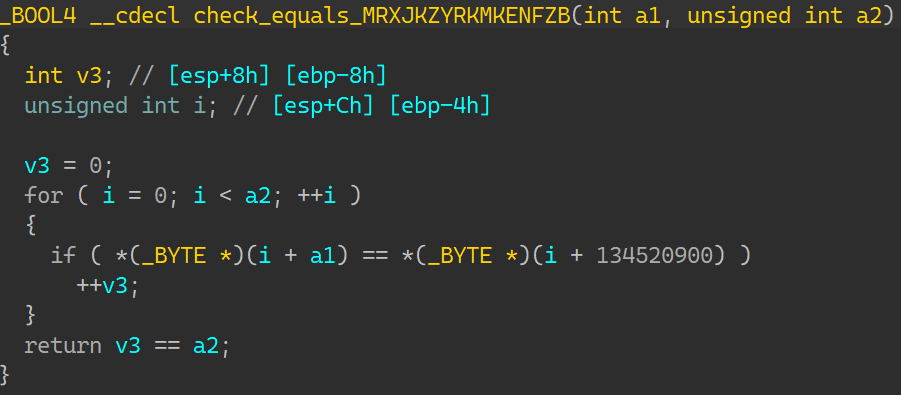
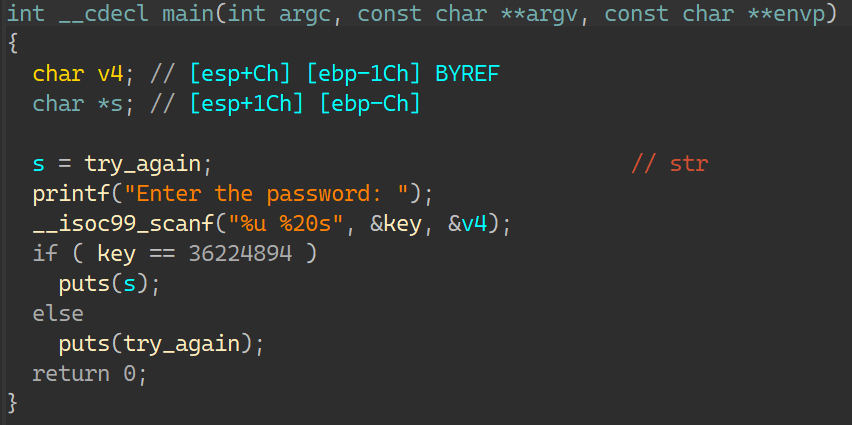
00_angr_find IDA分析:
一个很简单的函数,按照介绍所说,需要让angr帮忙计算出输入的内容就是这里的比较数据:FPQPMQXT;那要怎么去写约束得到正确的输入呢?当然是要让状态走到输出’Good Job.’这一条,而不能走向’Try again.’;如此一来输入只能是比较数据;所以找到这条指令的地址:
接下来就可以写执行脚本了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import sysimport angrdef main (argv ): path_to_binary = '../program/00_angr_find' project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() simulation = project.factory.simgr(initial_state) print_good_addr = 0x0804867D simulation.explore(find=print_good_addr) if simulation.found: solution_state = simulation.found[0 ] print (solution_state.posix.dumps(sys.stdin.fileno())) else : raise Exception('Could not find solution' ) if __name__ == '__main__' : main(sys.argv)
小结:
运用sys库是需要得到标准输入 -> sys.stdin.fileno() ;
angr.Project(执行的二进制文件地址) -> 打开二进制文件;
project.factory.entry_state() -> 创建空白的执行环境;
project.factory.simgr(上下文对象) -> 创建模拟器;
simulation.explore(find = 搜索程序执行路径的地址) -> 执行路径探索;
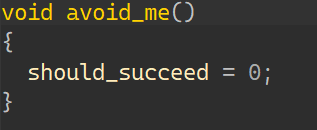
01_angr_avoid 这道题和00其实很像,只是在main函数里塞了很多大量的垃圾代码,直接用find输出正确的地址就找不到;
看到maybe_good函数:
以及在main函数里经常出现的avoid_me函数:
可以知道,如果进入了avoid_me后,再进入maybe_good就与输出Good Job无缘了,所以在寻找怎样输入才能导致输出正确的时候,可以再加一个约束,约束状态不要进入avoid_me;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import sysimport angrdef main (argv ): path_to_binary = '../program/01_angr_avoid' project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() simulation = project.factory.simgr(initial_state) print_good_addr = 0x080485E0 aovid_me_addr = 0x080485A8 simulation.explore(find=print_good_addr, avoid=aovid_me_addr) if simulation.found: solution_state = simulation.found[0 ] print (solution_state.posix.dumps(sys.stdin.fileno())) else : raise Exception('Could not find solution' ) if __name__ == '__main__' : main(sys.argv)
小结:
simulation.explore(find = 要搜索的路径地址, avoid = 要排除执行路径地址) -> 路径探索
simulation.found -> 搜索结果集合,这是一个python list 对象
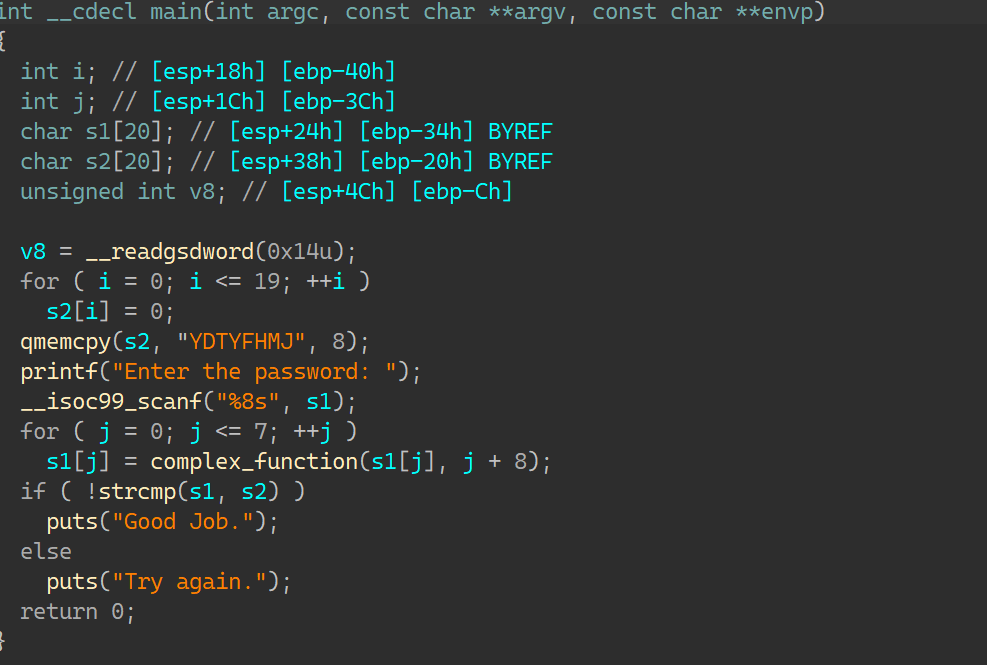
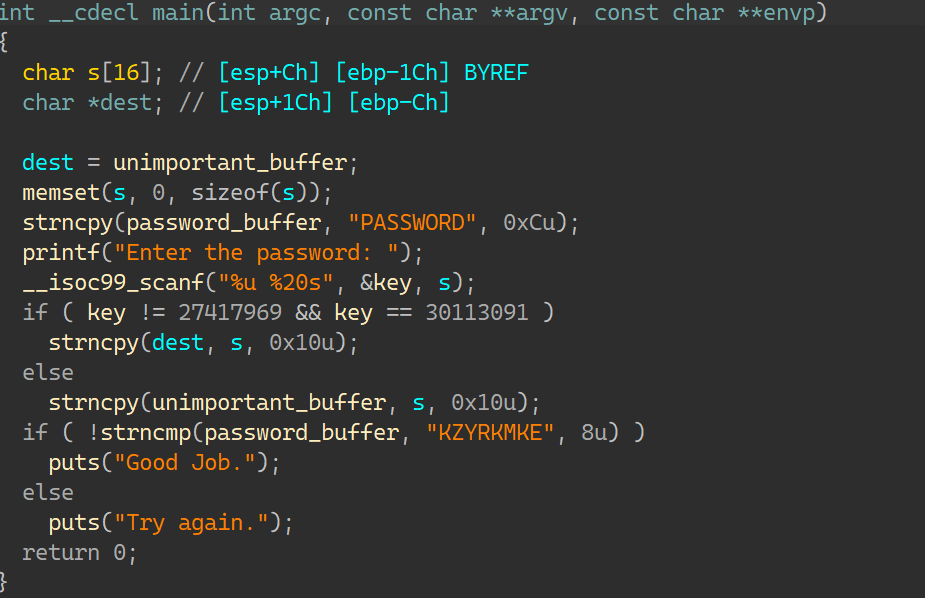
02_angr_find_condition IDA:
与00比较,在进行判断字符串的时候进行了一次运算,而在汇编层可以看到 puts(“Good Job.”) 这条指令来自很多地址,被混淆打乱了:
所以这次不能用 find=地址 来得到要找到的正确输入了;所以需要构建explore() 函数的回调函数;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import sysimport angrdef good_job (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return 'Good Job' in str (stdout_output) def try_again (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return 'Try again' in str (stdout_output) def main (argv ): path_to_binary = './02_angr_find_condition' project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() simulation = project.factory.simgr(initial_state) simulation.explore(find=good_job, avoid=try_again) if simulation.found: solution_state = simulation.found[0 ] print (solution_state.posix.dumps(sys.stdin.fileno())) else : raise Exception('Could not find solution' ) if __name__ == '__main__' : main(sys.argv)
小结:
simulation.explore(find = 回调函数, avoid = 回调函数) -> 路径探索
explore() 函数的回调函数格式为:
def recall_explore(state) :
…
return True / False # True 意思是发现了该路径,False 则是忽略
state.posix.dumps(sys.stdout.fileno()) -> 获取模拟执行的控制台输出
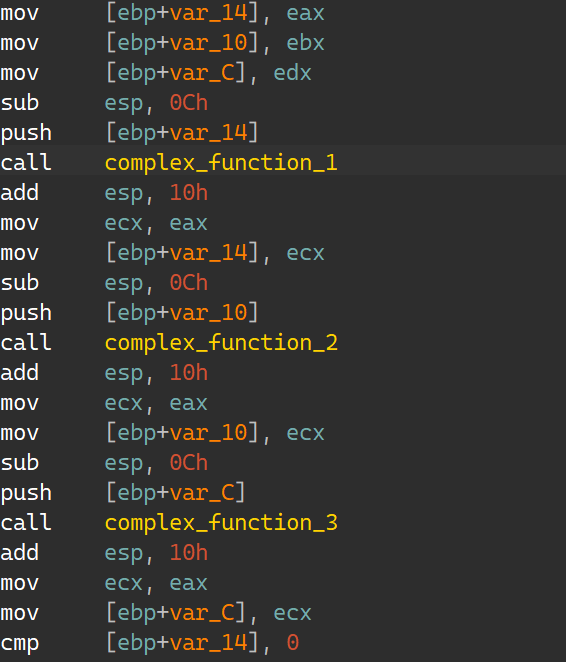
03_angr_symbolic_registers IDA:
这次让输入三次内容,三次经过不同的加密,最后经过 if 判断来找结果;
汇编层:
虽然伪代码显示v5,v6,v8都变量都是栈里的数据,但汇编层显示出,它们是由寄存器eax,ebx,edx搬运进栈后才会是对应栈数据;
那么已知运算结果(怎样是正确的输出),以及运算过程由angr自己去运行;那么就需要设未知数进行求解,把寄存器设为未知数的过程,便称为符号化寄存器,也可以叫变量化寄存器;这一步就类似于Z3里的设置未知变量模型了;
这里需要用到一个库:claripy,下载angr自带的;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import sysimport angrimport claripydef main (): binary_path = '../program/03_angr_symbolic_registers' project = angr.Project(binary_path) start_addr = 0x0804890E initial_state = project.factory.blank_state(addr=start_addr) bit_length = 32 psd0 = claripy.BVS('psd0' , bit_length) psd1 = claripy.BVS('psd1' , bit_length) psd2 = claripy.BVS('psd2' , bit_length) initial_state.regs.eax = psd0 initial_state.regs.ebx = psd1 initial_state.regs.edx = psd2 simulation = project.factory.simgr(initial_state) def good_job (state ): stdout_content = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_content def fail (state ): stdout_content = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_content simulation.explore(find=good_job, avoid=fail) if simulation.found: solution_state = simulation.found[0 ] solution0 = solution_state.se.eval (psd0) solution1 = solution_state.se.eval (psd1) solution2 = solution_state.se.eval (psd2) solution = '%x %x %x' % (solution0, solution1, solution2) print (solution) else : raise Exception('Could not find the solution' ) if __name__ == '__main__' : main()
小结:
project.factory.blank_state(addr=start_address) -> 创建自定义入口的状态上下文
initial_state.regs -> 操作状态上下文的寄存器
claripy.BVS(‘变量名’, 变量大小) -> 创建求解变量
solution_state.se.eval(变量) -> 求解符号变量
solution = ‘%x %x %x’ % (solution0, solution1, solution2) -> 标准输出格式
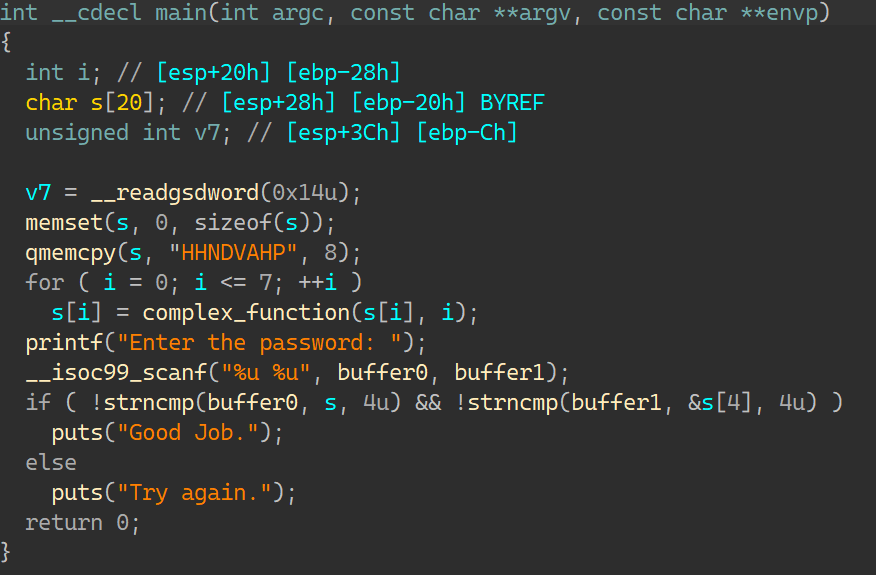
04_angr_symbolic_stack IDA:
这个函数是main里的唯一一个指令;查看汇编可以发现v1,v2变量不是由寄存器传到栈上,是直接输入的栈上的,那么这次做的便是符号化栈;将栈上的数据设置为未知数,所以需要去平衡栈;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import sysimport angrimport claripydef main (): binary_path = './04_angr_symbolic_stack' project = angr.Project(binary_path) start_addr = 0x08048697 initial_state = project.factory.blank_state(addr=start_addr) initial_state.regs.ebp = initial_state.regs.esp password0 = claripy.BVS('password0' , 32 ) password1 = claripy.BVS('password1' , 32 ) padding_length_in_bytes = 8 initial_state.regs.esp -= padding_length_in_bytes initial_state.stack_push(password0) initial_state.stack_push(password1) simulation = project.factory.simgr(initial_state) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again' in stdout_output simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution0 = solution_state.se.eval (password0) solution1 = solution_state.se.eval (password1) solution = '%u %u' % (solution0, solution1) print (solution) else : raise Exception('could not find the solution' ) if __name__ == '__main__' : main()
05_angr_symbolic_memory IDA:
发现这次输入的内容被存到了4个地方,这4个地方都是.bss段上的内存(unk开头的指针以及user_input),之后计算并比较;和之前2题一样,这次需要的是符号化内存;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import angrimport sysimport claripyfrom Crypto.Util.number import long_to_bytesdef main (): binary_path = './05_angr_symbolic_memory' project = angr.Project(binary_path) start_addr = 0x08048601 initial_state = project.factory.blank_state(addr=start_addr) password0 = claripy.BVS('password0' , 64 ) password1 = claripy.BVS('password1' , 64 ) password2 = claripy.BVS('password2' , 64 ) password3 = claripy.BVS('password3' , 64 ) password0_addr = 0x09FD92A0 password1_addr = 0x09FD92A8 password2_addr = 0x09FD92B0 password3_addr = 0x09FD92B8 initial_state.memory.store(password0_addr, password0) initial_state.memory.store(password1_addr, password1) initial_state.memory.store(password2_addr, password2) initial_state.memory.store(password3_addr, password3) simulation = project.factory.simgr(initial_state) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_output simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution0 = solution_state.se.eval (password0) solution1 = solution_state.se.eval (password1) solution2 = solution_state.se.eval (password2) solution3 = solution_state.se.eval (password3) solution = long_to_bytes(solution0)+b' ' +long_to_bytes(solution1)+b' ' +long_to_bytes(solution2)+b' ' +long_to_bytes(solution3) print (solution.decode()) else : raise Exception('Could not find solution' ) if __name__ == '__main__' : main()
小结:
initial_state.memory.store(地址,数据) -> 初始化内存地址中的数据
long_to_byte函数 -> 规范输出
06_angr_symbolic_dynamic_memory IDA:
可以看到这次用了malloc分配了动态内存,而scanf输入则直接放到了这些内存上,下面步骤都和之前一样,所以这次要做的就是符号化动态内存;但动态内存没有固定的地址,所以需要用到buffer在.bss段上的指针;Angr可以不用创建新内存(malloc),直接指向内存中一个任意位置即可;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import sysimport angrimport claripyfrom Crypto.Util.number import long_to_bytesdef main (): binary_path = '../program/06_angr_symbolic_dynamic_memory' project = angr.Project(binary_path) start_addr = 0x08048699 initial_state = project.factory.blank_state(addr=start_addr) password0 = claripy.BVS('password0' , 64 ) password1 = claripy.BVS('password1' , 64 ) fake0_addr = 0x09FD9160 fake1_addr = 0x09FD9180 buffer0_addr = 0x09FD92AC buffer1_addr = 0x09FD92B4 initial_state.memory.store(buffer0_addr, fake0_addr, endness=project.arch.memory_endness) initial_state.memory.store(buffer1_addr, fake1_addr, endness=project.arch.memory_endness) initial_state.memory.store(fake0_addr, password0) initial_state.memory.store(fake1_addr, password1) simulation = project.factory.simgr(initial_state) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_output simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution0 = solution_state.se.eval (password0) solution1 = solution_state.se.eval (password1) solution = long_to_bytes(solution0) + b' ' + long_to_bytes(solution1) print (solution) print (solution.decode()) else : raise Exception('Could not find solution' ) if __name__ == '__main__' : main()
小结:
initial_state.memory.store(地址,数据,endness = 数据字节顺序) -> 设置初始化内存数据
project.arch.memory_endness -> 指的是内存字节顺序
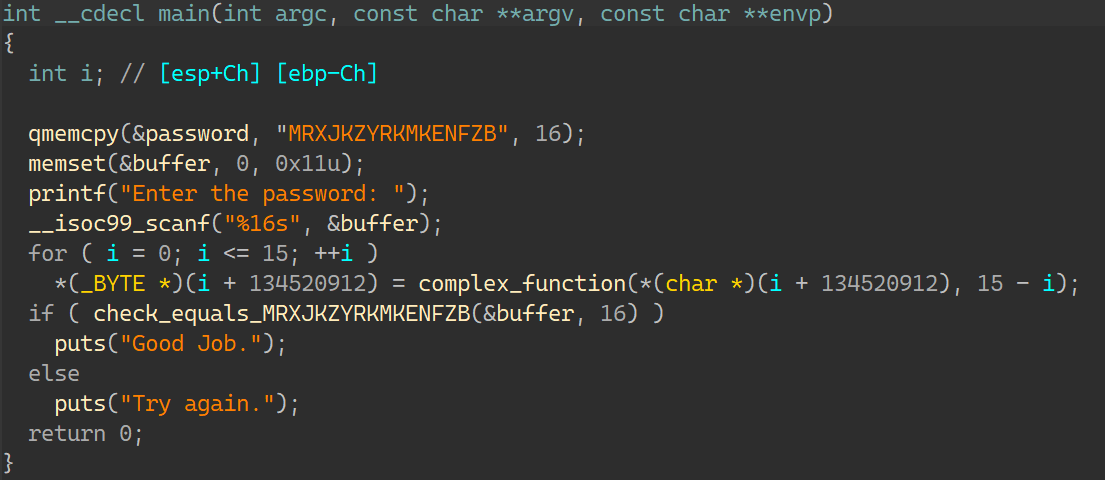
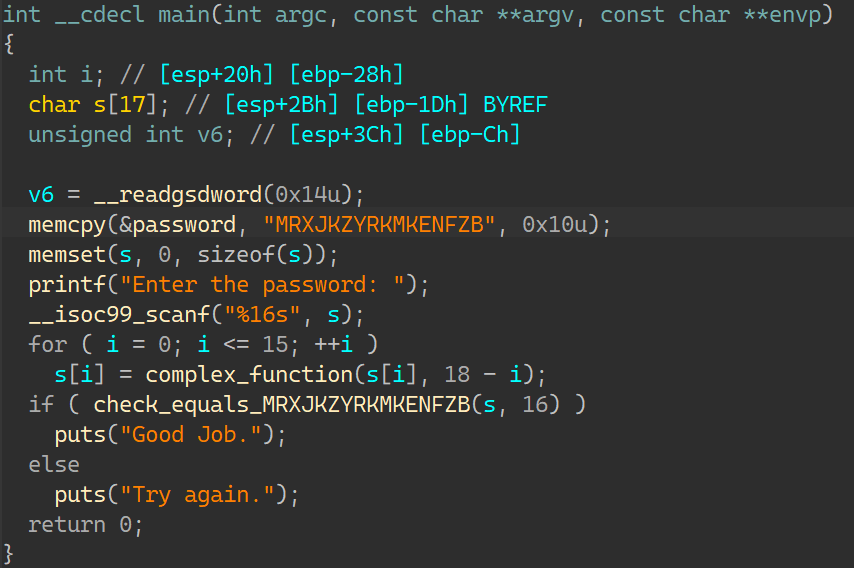
07_angr_symbolic_file IDA:
ignore_me函数:
输入的内容先保存到buffer里,接着用ignore_me函数将buffer里的内容存到叫做MRXJKZYR.txt的新建文件里;之后返回到主函数,初始化buffer;然后打开这个新建文件,读取里面的内容再到buffer里,最后运算比较;这次需要做的便是符号化文件;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import sysimport angrimport claripyfrom Crypto.Util.number import long_to_bytesdef main (): binary_path = '../program/07_angr_symbolic_file' project = angr.Project(binary_path) start_addr = 0x080488EA filename = 'MRXJKZYR.txt' symbolic_file_size_bytes = 64 password = claripy.BVS('password' , symbolic_file_size_bytes * 8 ) password_file = angr.SimFile(filename, content=password, size=symbolic_file_size_bytes) initial_state = project.factory.blank_state(addr=start_addr, fs={filename: password_file}) simulation = project.factory.simgr(initial_state) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_output simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution = long_to_bytes(solution_state.solver.eval (password)) print (solution.decode()) else : raise Exception('Could not find solution' ) if __name__ == '__main__' : main()
小结:
angr.storage.SimFile(文件名,文件内容, size = 文件大小) -> 创建一个模拟文件,当有被执行的程序fopen 打开文件时,可以控制其里面的内容
initial_state.posix.fs -> 状态上下文的文件系统对象
08_angr_constraints IDA:
输入字串后进行加密,之后经过检查函数判断;
这次可以控制输入的内容最后导致password地址的字串是否变为了正确的;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import sysimport angrimport claripyfrom Crypto.Util.number import long_to_bytesdef main (): binary_path = './08_angr_constraints' project = angr.Project(binary_path) start_addr = 0x08048625 initial_state = project.factory.blank_state(addr=start_addr) password = claripy.BVS('password' , 16 *8 ) password_addr = 0x0804A050 initial_state.memory.store(password_addr, password) simulation = project.factory.simgr(initial_state) addr_to_check_constraint = 0x08048669 simulation.explore(find=addr_to_check_constraint) if simulation.found: solution_state = simulation.found[0 ] constrained_parameter_addr = 0x0804A050 constrained_parameter_size_bytes = 16 constrained_parameter_bitvector = solution_state.memory.load(constrained_parameter_addr, constrained_parameter_size_bytes) constrained_parameter_desired_value = 'MRXJKZYRKMKENFZR' constrained_expression = constrained_parameter_bitvector == constrained_parameter_desired_value solution_state.add_constraints(constrained_expression) solution = long_to_bytes(solution_state.se.eval (password)) print (solution.decode()) else : raise Exception('Could not find the sokution' ) if __name__ == '__main__' : main()
小结:
solution_state.memory.load(内存地址,内存大小) -> 加载内存
solution_state.add_constraints(约束条件) -> 添加约束条件
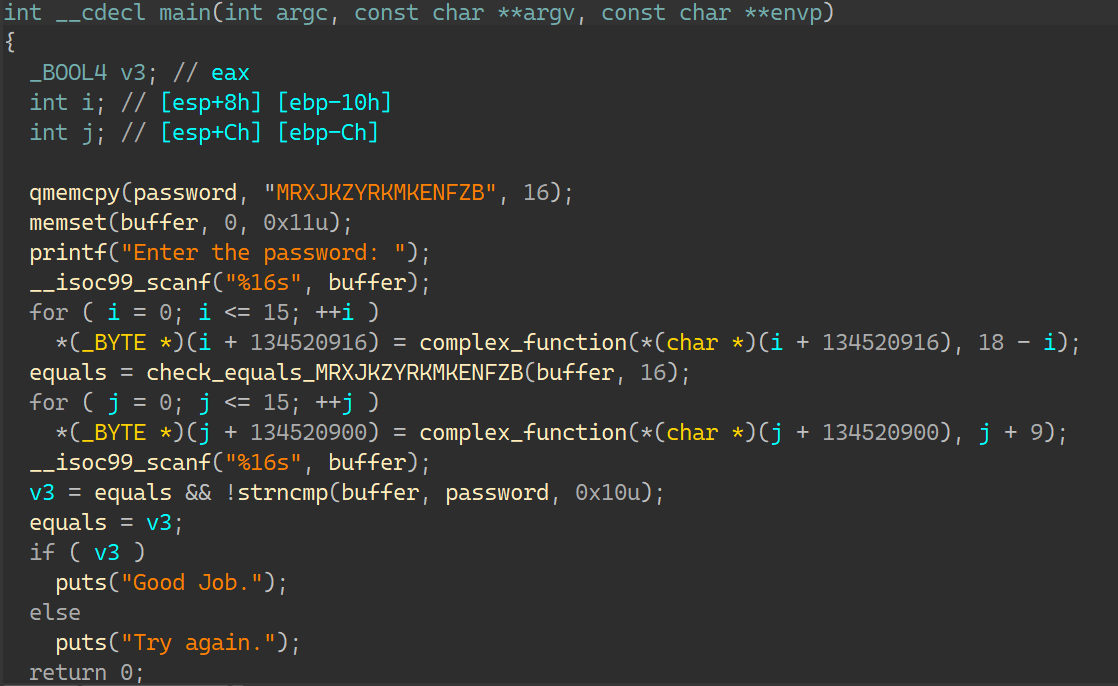
09_angr_hooks IDA:
分别输入两次加密比较;
这题是要求注入,模拟equals函数的功能:
注入地址当然就是调用这个函数的地址;angr里的注入类似于CE,开辟一块新区块,然后在这里写入注入内容,最后跳回注入地址的后一地址;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import sysimport angrimport claripydef main (): binary_path = './09_angr_hooks' project = angr.Project(binary_path) initial_state = project.factory.entry_state() check_equals_caller_addr = 0x080486A9 instruction_to_skip_length = 0x080486BB - 0x080486A9 @project.hook(check_equals_caller_addr, length = instruction_to_skip_length ) def skip_check_equals (state ): user_input_buffer_addr = 0x0804A054 user_input_buffer_length = 16 user_input_string = state.memory.load( user_input_buffer_addr, user_input_buffer_length ) check_against_string = 'MRXJKZYRKMKENFZB' state.regs.eax = claripy.If( user_input_string == check_against_string, claripy.BVV(1 , 32 ), claripy.BVV(0 , 32 ) ) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_output simulation = project.factory.simgr(initial_state) simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution = solution_state.posix.dumps(sys.stdin.fileno()) print (solution.decode()) else : raise Exception('Could not find the solution' ) if __name__ == '__main__' : main()
小结:
Hook回调函数格式:
@project.hook(Hook地址,执行完Hook函数后指令往后跳转n字节)
pass
claripy.If(条件,条件为True时的返回值,条件为False时的返回值) -> 创建条件判断
claripy.BVV(值,值大小) -> 创建一个数值
10_angr_simprocedures IDA:
相对于上一道题更简单,只用输入一次;
但equals函数却混淆为了多个分支,和02一样,这样就没办法在一个地址注入;
所以可以用Angr 的Hook Symbol 来实现对check_equals() 函数的注入;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import angrimport sysimport claripydef main (): binary_path = './09_angr_hooks' project = angr.Project(binary_path) initial_state = project.factory.entry_state() class mySimPro (angr.SimProcedure ): def run (self, user_input_addr, user_input_length ): angr_bvs = self.state.memory.load( user_input_addr, user_input_length ) desired = 'MRXJKZYRKMKENFZB' return claripy.If( desired == angr_bvs, claripy.BVV(1 ,32 ), claripy.BVV(0 ,32 ) ) check_symbol = 'check_equals_MRXJKZYRKMKENFZB' project.hook_symbol(check_symbol,mySimPro()) simulation = project.factory.simgr(initial_state) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_output simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution = solution_state.posix.dumps(sys.stdin.fileno()) print (solution.decode()) else : raise Exception('Could not find the solution' ) if __name__ == '__main__' : main()
小结:
Hook 回调函数格式:
class ReplacementCheckEquals(angr.SimProcedure):
def run(self, Hook的函数参数列表):
….
return 函数返回值 # 如果是void函数可以省略
project.hook_symbol(要Hook的函数名,SimProcedure类实例)
11_angr_sim_scanf IDA:
这道题是注入系统函数scanf改变符号;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import angrimport sysimport claripydef main (argv ): path_to_binary = argv[1 ] project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() class ReplacementScanf (angr.SimProcedure ): def run (self, format_string, scanf0_address, scanf1_address ): scanf0 = claripy.BVS('scanf0' , 4 * 8 ) scanf1 = claripy.BVS('scanf1' , 4 * 8 ) self.state.memory.store(scanf0_address, scanf0, endness=project.arch.memory_endness) self.state.memory.store(scanf1_address, scanf1, endness=project.arch.memory_endness) self.state.globals ['solution0' ] = scanf0 self.state.globals ['solution1' ] = scanf1 scanf_symbol = '__isoc99_scanf' project.hook_symbol(scanf_symbol, ReplacementScanf()) simulation = project.factory.simgr(initial_state) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return 'Good Job' in str (stdout_output) def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return 'Try again' in str (stdout_output) simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] stored_solutions0 = solution_state.globals ['solution0' ] stored_solutions1 = solution_state.globals ['solution1' ] solution0 = solution_state.se.eval (stored_solutions0) solution1 = solution_state.se.eval (stored_solutions1) print (solution0,solution1) else : raise Exception('Could not find the solution' ) if __name__ == '__main__' : main()
12_angr_veritesting 这个示例和01 题是一样的,唯独不同的一点是这个循环比之前的要大,导致直接用01 题的解题方法不能直接计算出结果,因为循环过大导致路径爆炸,所以在执行的时候会消耗很多资源.
project.factory.simgr() 函数提供veritesting 参数来指定是否要自动合并路径,避免路径爆炸的问题.具体细节参考论文:https://users.ece.cmu.edu/~dbrumley/pdf/Avgerinos%20et%20al._2014_Enhancing%20Symbolic%20Execution%20with%20Veritesting.pdf
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import sysimport angrdef main (): binary_path = './/12_angr_veritesting' project = angr.Project(binary_path) initial_state = project.factory.entry_state() simulation = project.factory.simgr(initial_state, veritesting=True ) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Good Job.' in stdout_output def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return b'Try again.' in stdout_output simulation.explore(find=is_successful, avoid=should_abort) if simulation.found: solution_state = simulation.found[0 ] solution = solution_state.posix.dumps(sys.stdin.fileno()) print (solution) else : raise Exception('Could not find the solution' ) if __name__ == '__main__' : main()
小结:
project.factory.simgr(初始化状态,veritesting = True) -> veritesting 默认为False
13_angr_static_binary 与01一样,唯一不同的这个程序是静态链接编译,程序中包含libc的函数实现;在CTF中,这些函数会隐藏一些出题人的坑,或者这些函数不适配当前的系统;所以需要注入这些libc函数;
Angr库里自带一部分打包好的libc函数,直接导入即可;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import angrimport sysproject = angr.Project(sys.argv[1 ]) initial_state = project.factory.entry_state() simulation = project.factory.simgr(initial_state,veritesting = True ) project.hook(0x804ed40 , angr.SIM_PROCEDURES['libc' ]['printf' ]()) project.hook(0x804ed80 , angr.SIM_PROCEDURES['libc' ]['scanf' ]()) project.hook(0x804f350 , angr.SIM_PROCEDURES['libc' ]['puts' ]()) project.hook(0x8048d10 , angr.SIM_PROCEDURES['glibc' ]['__libc_start_main' ]()) def is_successful (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return 'Good Job.' in str (stdout_output) def should_abort (state ): stdout_output = state.posix.dumps(sys.stdout.fileno()) return 'Try again.' in str (stdout_output) simulation.explore(find = is_successful,avoid = should_abort) if simulation.found : solution_state = simulation.found[0 ] print (solution_state.posix.dumps(sys.stdin.fileno()))
小结:
angr.SIM_PROCEDURES[ 系统库名 ] [ 系统函数名 ] () -> 获取Angr 内部实现的系统函数
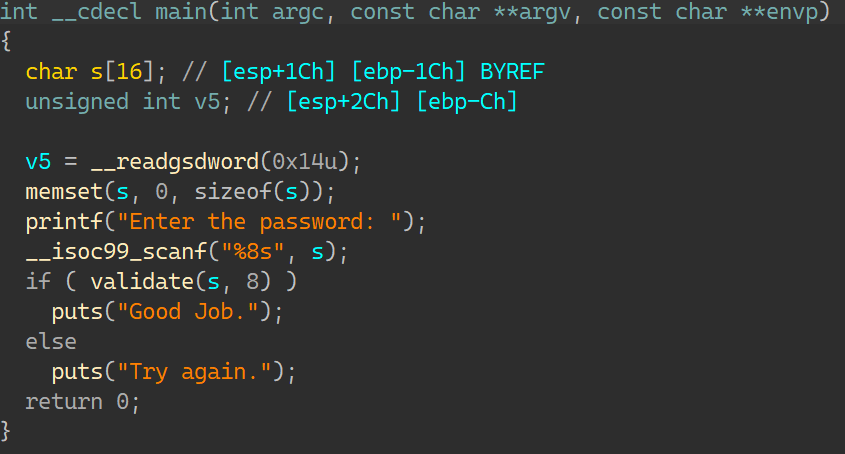
14_angr_shared_library IDA:
类似01,但validate函数是一个动态链接库的函数;
对动态链接库中的_validate 函数进行符号执行;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def main (argv ): path_to_binary = sys.argv[1 ] base = 0x400000 project = angr.Project(path_to_binary, load_options={ 'main_opts' : { 'custom_base_addr' : base } }) buffer_pointer = claripy.BVV(0x3000000 , 32 ) validate_function_address = base + 0x6D7 initial_state = project.factory.call_state(validate_function_address, buffer_pointer,claripy.BVV(8 , 32 )) password = claripy.BVS('password' , 8 * 8 ) initial_state.memory.store(buffer_pointer, password) simulation = project.factory.simgr(initial_state) simulation.explore(find = base + 0x783 ) if simulation.found: solution_state = simulation.found[0 ] solution_state.add_constraints(solution_state.regs.eax != 0 ) solution = solution_state.se.eval (password) print (solution)
15_angr_arbitrary_read IDA:
控制输入;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def main (argv ): path_to_binary = argv[1 ] project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() class ReplacementScanf (angr.SimProcedure ): def run (self, format_string, check_key_address,input_buffer_address ): scanf0 = claripy.BVS('scanf0' , 4 * 8 ) scanf1 = claripy.BVS('scanf1' , 20 * 8 ) for char in scanf1.chop(bits=8 ): self.state.add_constraints(char >= '0' , char <= 'z' ) self.state.memory.store(check_key_address, scanf0, endness=project.arch.memory_endness) self.state.memory.store(input_buffer_address, scanf1,endness=project.arch.memory_endness) self.state.globals ['solution0' ] = scanf0 self.state.globals ['solution1' ] = scanf1 scanf_symbol = '__isoc99_scanf' project.hook_symbol(scanf_symbol, ReplacementScanf()) def check_puts (state ): puts_parameter = state.memory.load(state.regs.esp + 4 , 4 , endness=project.arch.memory_endness) if state.se.symbolic(puts_parameter): good_job_string_address = 0x4D525854B copied_state = state.copy() copied_state.add_constraints(puts_parameter == good_job_string_address) if copied_state.satisfiable(): state.add_constraints(puts_parameter == good_job_string_address) return True else : return False else : return False simulation = project.factory.simgr(initial_state) def is_successful (state ): puts_address = 0x8048370 if state.addr == puts_address: return check_puts(state) else : return False simulation.explore(find=is_successful) if simulation.found: solution_state = simulation.found[0 ] solution0 = solution_state.se.eval (solution_state.globals ['solution0' ]) solution1 = solution_state.se.eval (solution_state.globals ['solution1' ],cast_to=bytes ) print (solution0,solution1)
小结:
state.copy() -> 复制状态上下文
state.satisfiable() -> 判断当前的所有约束是否有解
solution_state.se.eval(求解变量,cast_to=bytes) -> 序列化变量内容为字符串
16_angr_arbitrary_write IDA:
控制写入内存;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 def main (argv ): path_to_binary = argv[1 ] project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() class ReplacementScanf (angr.SimProcedure ): def run (self, format_string, check_key ,input_buffer ): scanf0 = claripy.BVS('scanf0' , 4 * 8 ) scanf1 = claripy.BVS('scanf1' , 20 * 8 ) for char in scanf1.chop(bits=8 ): self.state.add_constraints(char >= '0' , char <= 'z' ) self.state.memory.store(check_key, scanf0, endness=project.arch.memory_endness) self.state.memory.store(input_buffer, scanf1, endness=project.arch.memory_endness) self.state.globals ['solution0' ] = scanf0 self.state.globals ['solution1' ] = scanf1 scanf_symbol = '__isoc99_scanf' project.hook_symbol(scanf_symbol, ReplacementScanf()) def check_strncpy (state ): strncpy_dest = state.memory.load(state.regs.esp + 4 , 4 , endness=project.arch.memory_endness) strncpy_src = state.memory.load(state.regs.esp + 8 , 4 , endness=project.arch.memory_endness) strncpy_len = state.memory.load(state.regs.esp + 12 , 4 , endness=project.arch.memory_endness) src_contents = state.memory.load(strncpy_src, strncpy_len) if state.se.symbolic(strncpy_dest) and state.se.symbolic(src_contents) : if state.satisfiable(extra_constraints=(src_contents[ -1 : -64 ] == 'KZYRKMKE' ,strncpy_dest == 0x4D52584C )): state.add_constraints(src_contents[ -1 : -64 ] == 'KZYRKMKE' ,strncpy_dest == 0x4D52584C ) return True else : return False else : return False simulation = project.factory.simgr(initial_state) def is_successful (state ): strncpy_address = 0x8048410 if state.addr == strncpy_address: return check_strncpy(state) else : return False simulation.explore(find=is_successful) if simulation.found: solution_state = simulation.found[0 ] solution0 = solution_state.se.eval (solution_state.globals ['solution0' ]) solution1 = solution_state.se.eval (solution_state.globals ['solution1' ],cast_to=bytes ) print (solution0,solution1)
小结:
state.satisfiable(extra_constraints=(条件1,条件2)) -> 合并多个条件计算是否存在满足约束的解(注意两个或多个条件之间是And 合并判断,不是Or )
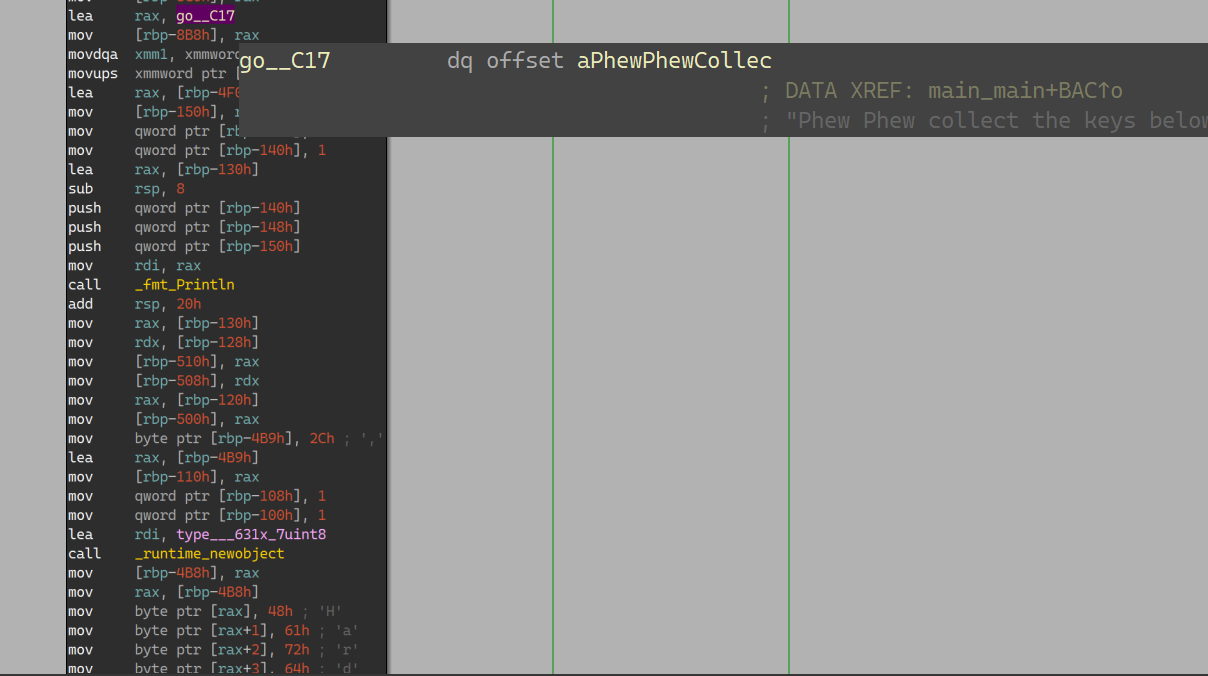
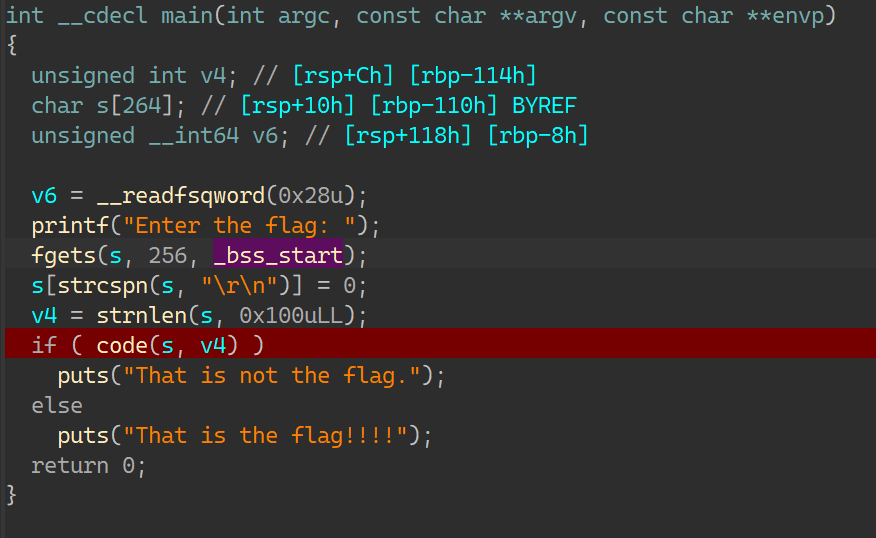
17_angr_arbitrary_jump IDA:
这是一个栈溢出;
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def main (argv ): path_to_binary = argv[1 ] project = angr.Project(path_to_binary) initial_state = project.factory.entry_state() simulation = project.factory.simgr( initial_state, save_unconstrained=True , stashes={ 'active' : [initial_state], 'unconstrained' : [], 'found' : [], 'not_needed' : [] } ) class ReplacementScanf (angr.SimProcedure ): def run (self, format_string, input_buffer_address ): input_buffer = claripy.BVS('input_buffer' , 64 * 8 ) for char in input_buffer.chop(bits=8 ): self.state.add_constraints(char >= '0' , char <= 'z' ) self.state.memory.store(input_buffer_address, input_buffer, endness=project.arch.memory_endness) self.state.globals ['solution' ] = input_buffer scanf_symbol = '__isoc99_scanf' project.hook_symbol(scanf_symbol, ReplacementScanf()) while (simulation.active or simulation.unconstrained) and (not simulation.found): for unconstrained_state in simulation.unconstrained: def should_move (s ): return s is unconstrained_state simulation.move('unconstrained' , 'found' , filter_func=should_move) simulation.step() if simulation.found: solution_state = simulation.found[0 ] solution_state.add_constraints(solution_state.regs.eip == 0x4D525849 ) solution = solution_state.se.eval (solution_state.globals ['solution' ],cast_to = bytes ) print (solution)
总结: 0002讲解的是基础操作;0307讲解的是符号化常见内容;08讲解的是求解内容约束;0908讲解如何注入来替换函数或者增加函数;1114讲解的都是进阶的内容;15~17讲解的都和控制有关,与pwn题相关;
真正吃透angr会花更多的时间,但真正强化二进制能力的并不是如何去使用angr,而是明白angr函数针对于汇编层的操作;